











Eingebettete Systeme verlassen sich stark auf deterministisches Verhalten. Wenn ein Gerät betrieben wird, muss es innerhalb bestimmter Bedingungen vorhersehbar auf Eingaben reagieren. Zustandsmaschinen-Diagramme, die oft Teil der Unified Modeling Language (UML) sind, dienen als Bauplan für dieses Verhalten. Bei der Übersetzung eines Diagramms in Code verbergen sich jedoch häufig Fehler. Logikfehler in endlichen Zustandsmaschinen (FSMs) können zu Systemhängen, unerwarteten Neustarts oder Sicherheitsrisiken führen. 🚨
Diese Anleitung bietet einen strukturierten Ansatz zur Identifizierung und Behebung von Logikfehlern in Zustandsmaschinen-Entwürfen. Durch das Verständnis der Feinheiten von Zustandsübergängen, Wächterbedingungen und hierarchischen Strukturen können Entwickler sicherstellen, dass ihre eingebettete Software wie beabsichtigt funktioniert.
🧩 Verständnis der Komplexität von FSMs
Eine Zustandsmaschine definiert die möglichen Zustände eines Systems und wie es zwischen ihnen wechselt. In eingebetteten Kontexten beinhaltet dies oft Hardware-Interaktionen, Timer und externe Interrupts. Im Gegensatz zu einfachen prozeduralen Codeabschnitten bewahrt eine Zustandsmaschine den Kontext. Wenn dieser Kontext verloren geht oder beschädigt ist, versagt die Logik.
Häufige Szenarien, in denen FSMs entscheidend sind, umfassen:
- Kommunikationsprotokolle (z. B. UART, SPI, I2C-Zustandsverwaltung)
- Benutzeroberflächen-Navigation (z. B. Tastendrücke, Bildschirmwechsel)
- Energiesparmodi (z. B. Schlafzustand, aktiv, Bereitschaft)
- Motorkontrollsequenzen (z. B. Start, Lauf, Stop, Fehler)
Beim Fehlerbehebungsprozess ist es entscheidend, zwischen Implementierungsfehlern und Designfehlern zu unterscheiden. Ein Designfehler liegt vor, wenn das Diagramm selbst einen gültigen Zustand nicht abdeckt. Ein Implementierungsfehler tritt auf, wenn der Code nicht dem Diagramm folgt.
⚠️ Häufige Logikfehler in eingebetteten Zustandsmaschinen
Die Fehlersuche in der Zustandslogik erfordert ein scharfes Auge für Details. Bestimmte Fehlermuster treten häufig wiederholt auf. Die Erkennung dieser Muster beschleunigt den Behebungsprozess.
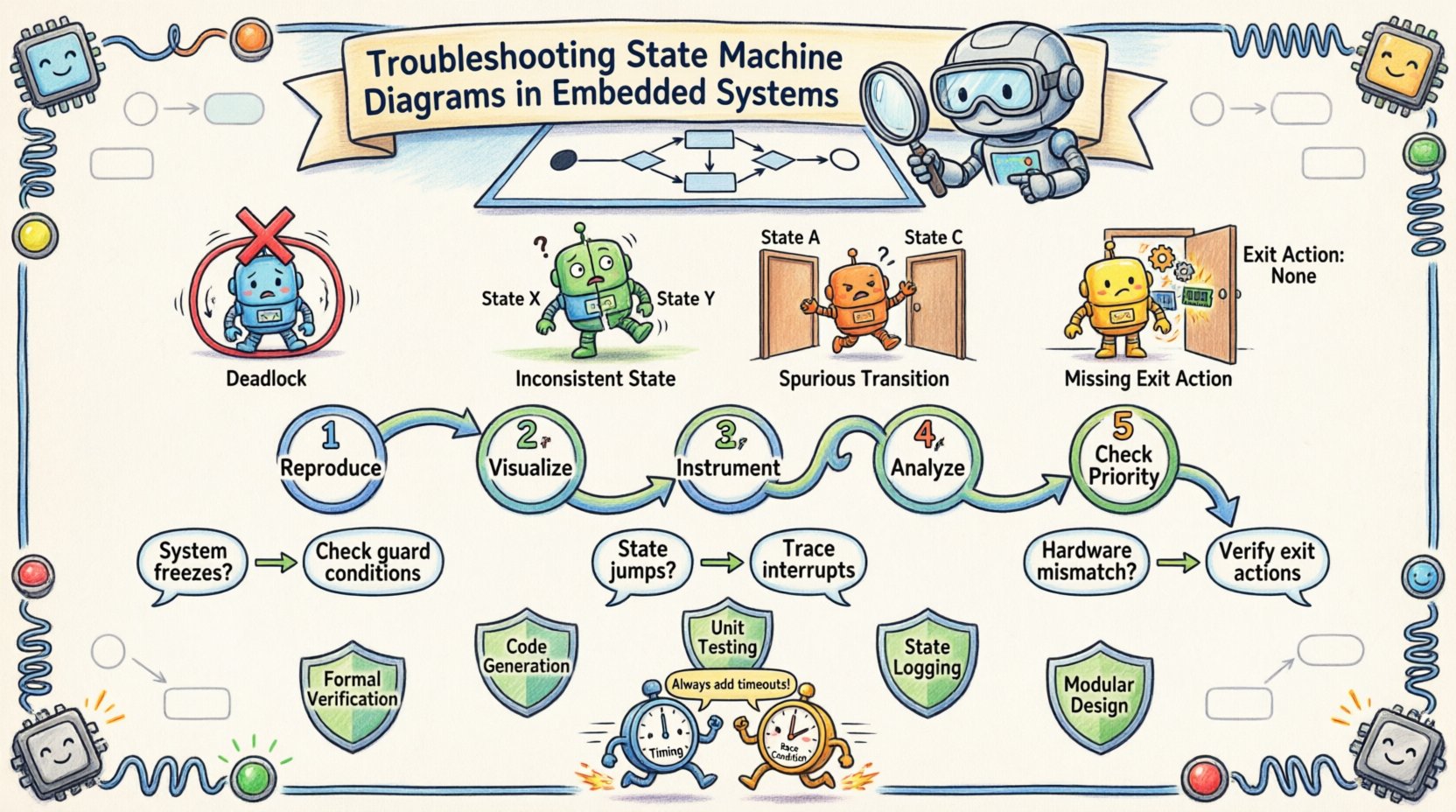
1. Der Deadlock-Szenario
Ein Deadlock tritt auf, wenn das System in einen Zustand gelangt, in dem keine Übergänge möglich sind, das System aber weder in einem End- noch in einem Fehlerzustand ist. Der Prozessor bleibt untätig und wartet auf ein Ereignis, das niemals eintreffen wird. Dies wird oft verursacht durch:
- Fehlende Standardübergänge (Selbstschleifen) für nicht behandelte Ereignisse.
- Wächterbedingungen, die immer falsch sind.
- Logik, die ein Ereignis-Flag löscht, bevor die Zustandsmaschine es prüft.
2. Spurious Übergänge
Spurious Übergänge treten auf, wenn das System in einen Zustand wechselt, in den es nicht wechseln sollte. Dies stammt meist aus:
- Mehrere Ereignisse, die den gleichen Übergangspfad auslösen, ohne dass eine geeignete Ausschlussbedingung besteht.
- Falsche Handhabung von Ereignis-Queues, bei denen ein altes Ereignis einen neuen Zustand auslöst.
- Gleichzeitige Zustände, die nicht ordnungsgemäß synchronisiert sind.
3. Inkonsistente Zustände
Dies tritt auf, wenn interne Variablen nicht mit dem aktuellen Zustand der Maschine übereinstimmen. Zum Beispiel könnte ein Motor im Diagramm im Zustand „Läuft“ sein, während der Hardware-Register „Gestoppt“ anzeigt. Diese Desynchronisation erzeugt Verwirrung für nachfolgende Übergänge.
4. Der fehlende Ausgangsaktion
Bei komplexen Maschinen erfordert das Verlassen eines Zustands oft eine Bereinigung. Wenn die Ausgangsaktion im Code fehlt, aber im Entwurf vorhanden ist, bleiben Ressourcen (wie Speicher oder Sperren) belegt. Im Laufe der Zeit führt dies zu einer Erschöpfung der Ressourcen.
📊 Fehlerarten im Vergleich zu Symptomen
Beziehen Sie sich auf die Tabelle unten, um beobachtbares Verhalten möglichen Ursachen zuzuordnen.
| Beobachtetes Symptom | Mögliche Ursache | Diagnosefokus |
|---|---|---|
| System hängt bei bestimmter Eingabe fest | Deadlock oder fehlender Übergang | Prüfen Sie die Ereigniswarteschlange und Wächterbedingungen |
| Zustand springt unerwartet | Falscher Übergang oder Rennbedingung | Untersuchen Sie die Interrupt-Zeit und Ereignis-Flags |
| Hardware stimmt nicht mit Zustand überein | Fehlende Aktion beim Verlassen oder Aktualisierung | Überprüfen Sie Hardware-Register-Schreibvorgänge beim Verlassen |
| Intermittierende Ausfälle unter Last | Zeitverzögerung oder Rennbedingung | Analysieren Sie den Stapelverbrauch und Timer-Intervalle |
| System startet im falschen Zustand | Initialisierungsfehler | Prüfen Sie den Reset-Handler und den Standardzustand |
🔍 Schritt-für-Schritt-Diagnoseablauf
Wenn Logikfehler auftreten, verhindert ein systematischer Ansatz verschwendete Zeit. Raten Sie nicht; messen Sie.
1. Problem reproduzieren
Stellen Sie sicher, dass der Fehler reproduzierbar ist. Wenn das Problem intermittierend auftritt, versuchen Sie, die Bedingungen zu isolieren. Dokumentieren Sie die Ereignisfolge, die zum Ausfall führt. Ein Zustandsmaschine ist deterministisch; wenn Sie die gleiche Folge auslösen, sollten Sie das gleiche Ergebnis erhalten.
2. Fluss visualisieren
Öffnen Sie das UML-Diagramm. Verfolgen Sie den Pfad visuell. Markieren Sie den Startzustand und den Zielzustand. Suchen Sie nach Lücken im Diagramm. Berücksichtigt das Diagramm jeden möglichen Eingang in jedem Zustand? Wenn eine Eingabe nicht gezeichnet ist, könnte der Code sie ignorieren oder falsch behandeln.
3. Code instrumentieren
Fügen Sie Protokollierung an Schlüsselübergangspunkten hinzu. Dazu sind keine teuren Werkzeuge erforderlich. Einfache Print-Anweisungen oder das Umschalten von GPIO-Pins können den Zustand des Systems zur Laufzeit aufdecken. Protokollieren Sie:
- Aktuelle Zustands-ID
- Auslösendes Ereignis
- Auswertung der Wächterbedingung
- Zielzustand
4. Analyse des Zustands-Eintritts und -Austritts
Stellen Sie sicher, dass die Ein- und Ausgangsaktionen ausgelöst werden. Oft findet der Übergang statt, aber die Nebenwirkungen (wie das Hochsetzen eines Pins) nicht. Stellen Sie sicher, dass die Zustandsmaschinenlogik die Hardware unmittelbar bei Eingang aktualisiert.
5. Überprüfen Sie die Ereignispriorisierung
Wenn mehrere Ereignisse gleichzeitig auftreten, welches hat Vorrang? Der Code muss eine klare Priorität definieren. Wenn der Code Ereignis A priorisiert, das Design aber Ereignis B erwartet, wird die Logik abweichen.
🧠 Tiefgang: Wächterbedingungen und Auslöseereignisse
Wächterbedingungen sind boolesche Ausdrücke, die wahr sein müssen, damit ein Übergang stattfindet. Sie sind die Logikgatter der Zustandsmaschine. Fehler hier sind subtil, weil der Übergangspfad existiert, die Bedingung ihn aber verhindert.
Häufige Fehler bei Wächterbedingungen
- Variablenbereich: Die in der Wächterbedingung verwendete Variable wird möglicherweise nicht wie erwartet aktualisiert. Wenn eine Flagge in einem Interrupt gesetzt wird, aber im Hauptloop gelesen wird, treten Zeitverzögerungsprobleme auf.
- Logische Negation: Ein einfacher Tippfehler, wie zum Beispiel das Verwenden von “
!=anstelle von “==, kann den gesamten Logikfluss umkehren. - Nebenwirkungen: Wächterbedingungen sollten im Allgemeinen schreibgeschützt sein. Wenn eine Wächterbedingung eine globale Variable ändert, entstehen versteckte Zustandsänderungen, die schwer nachzuvollziehen sind.
Feinheiten der Ereignisbehandlung
Ereignisse sind die Auslöser. Sie können sein:
- Signale:Asynchrone Eingaben (z. B. Tastendruck).
- Timer:Periodische Eingaben (z. B. Watchdog-Takt).
- Fehler:Ausnahmeeingaben (z. B. CRC-Fehler).
Stellen Sie sicher, dass die Ereignisquelle nach der Verarbeitung zurückgesetzt wird. Wenn eine Ereignisflagge weiterhin gesetzt bleibt, könnte die Zustandsmaschine dasselbe Ereignis zweimal verarbeiten, was zu einer falschen Übergangssituation führt.
🏗️ Verwaltung hierarchischer Zustände und Vererbung
Komplexe Systeme verwenden hierarchische Zustände, um Diagrammverwirrung zu reduzieren. Ein Elternzustand enthält Kindzustände. Übergänge können auf der Elternebene stattfinden und alle Kinder beeinflussen.
Probleme mit der Hierarchie
Beim Debuggen hierarchischer Zustände entsteht oft Verwirrung darüber, wo sich der Zustand tatsächlich befindet.
- Implizite Übergänge: Das Wechseln von einem Kindzustand zu einem Geschwisterzustand erfordert oft das Verlassen des Elternzustands. Stellen Sie sicher, dass die Austrittsaktionen des Elternzustands korrekt ausgeführt werden.
- Standard-Eintrittspunkte: Wenn ein Elternzustand betreten wird, welcher Kindzustand ist aktiv? Wenn der Standardkindzustand nicht definiert ist, kann das System in einem undefinierten Zustand verbleiben.
- Lokale vs. globale Übergänge: Ein Übergang, der in einem Kindzustand definiert ist, könnte durch ein Ereignis ausgelöst werden, das vom Elternzustand behandelt wird. Verstehen Sie den Geltungsbereich des Ereignisses.
Best Practices für Hierarchien
- Minimieren Sie die Verschachtelungstiefe. Tiefgehende Hierarchien sind schwer nachzuvollziehen.
- Verwenden Sie explizite Standardzustände für alle zusammengesetzten Zustände.
- Dokumentieren Sie das Verhalten der Austrittsaktionen des Elternzustands klar und eindeutig.
⏱️ Zeitverhalten und Rennbedingungen
Eingebettete Systeme arbeiten in Echtzeit. Zustandsmaschinen sind nicht immun gegen Zeitprobleme. Rennbedingungen treten auf, wenn das Ergebnis von der relativen Zeitfolge der Ereignisse abhängt.
Interrupt vs. Haupt-Schleife
Oft werden Zustandsereignisse in einer Interrupt-Service-Routine (ISR) erzeugt, aber in der Haupt-Schleife verarbeitet. Wenn die Haupt-Schleife langsam ist, können Ereignisse sich ansammeln. Wenn die ISR eine Kennung löscht, bevor die Haupt-Schleife sie prüft, geht Daten verloren.
Entprellung von Eingaben
Physische Tasten springen. Wenn die Zustandsmaschine einen einzigen Tastendruck als mehrere Drücke interpretiert, wird der Zustandsdiagramm falsch durchlaufen. Implementieren Sie die Entprelllogik innerhalb der Zustandsmaschine (z. B. einen „Warten“-Zustand), anstatt sich ausschließlich auf die Hardware zu verlassen.
Zeitüberschreitungen
Jeder Zustand, der auf eine externe Eingabe wartet, sollte eine Zeitüberschreitung haben. Wenn ein erwartetes Ereignis innerhalb einer festgelegten Dauer nicht eintrifft, sollte das System in einen Fehler- oder Wiederherstellungszustand wechseln. Dies verhindert die zuvor erwähnte Deadlock-Situation.
🛡️ Verhinderungsstrategien für eine robuste Gestaltung
Fehler zu beheben ist reaktiv. Sie zu vermeiden, ist proaktiv. Die folgenden Strategien verringern die Wahrscheinlichkeit von Logikfehlern in zukünftigen Projekten.
- Formale Verifikation: Wo immer möglich, verwenden Sie formale Methoden, um die Erreichbarkeit von Zuständen zu überprüfen. Dadurch wird sichergestellt, dass jeder Zustand erreichbar ist und keine Deadlocks bestehen.
- Code-Generierung: Generieren Sie Code aus dem Zustandsdiagramm-Modell. Dadurch wird die Lücke zwischen Design und Implementierung verkleinert und menschliche Fehler minimiert.
- Einheitstests: Behandeln Sie die Zustandsmaschine wie jedes andere Modul. Schreiben Sie Tests für jeden Zustand und jeden Übergang. Berücksichtigen Sie sowohl Erfolgspfade als auch Fehlerpfade.
- Zustandsprotokollierung: Fügen Sie einen Zustandslogger in die Firmware ein. In der Praxis kann diese Daten analysiert werden, um Probleme zu reproduzieren, ohne physischen Zugriff zu benötigen.
- Modulare Gestaltung: Teilen Sie große Zustandsmaschinen in kleinere, miteinander interagierende Teilmaschinen auf. Dadurch wird das mentale Modell vereinfacht und Fehler isoliert.
🧰 Werkzeuge und Analysetechniken
Während sich bestimmte Software-Tools unterscheiden, bleiben die zugrundeliegenden Analysetechniken konstant.
Statische Analyse
Führen Sie eine statische Analyse des Quellcodes durch. Suchen Sie nach:
- Unerreichbare Codeblöcke.
- Nicht verwendete Variablen in der Zustandslogik.
- Variablenverdeckung, die Zustandswerte verbergen könnte.
Dynamische Analyse
Verwenden Sie einen Debugger, um durch die Übergänge zu schrittweise zu gehen.
- Legen Sie Haltepunkte in den Zustands-Eintritts- und -Austrittsfunktionen fest.
- Beobachten Sie die Zustandsvariable während der Ausführung genau.
- Überwachen Sie die Eingangs-Warteschlange, um sicherzustellen, dass Ereignisse in der richtigen Reihenfolge verarbeitet werden.
Hardware-in-the-Loop-Tests
Testen Sie die Zustandsmaschine mit echten Hardware-Signalen. Simulierte Eingaben verpassen oft elektrische Eigenschaften wie Rauschen oder Latenz, die logische Fehler auslösen.
📝 Letzte Überlegungen zur Wartung
Die Wartung einer Zustandsmaschine erfordert Disziplin. Wenn sich die Anforderungen ändern, muss das Diagramm aktualisiert werden. Wenn das Diagramm nicht gemeinsam mit dem Code aktualisiert wird, sammelt sich schnell technische Schulden an. Eine Zustandsmaschine, die nicht mehr ihrem Diagramm entspricht, ist eine Zeitbombe.
Regelmäßige Überprüfungen der Zustandslogik sind unerlässlich. Wenn eine neue Funktion hinzugefügt wird, vergleichen Sie sie mit den bestehenden Übergängen. Stößt sie auf einen bestehenden Pfad? Führt sie zu einem neuen Deadlock? Indem man die Designdokumentation aktuell hält und den Code ausrichtet, bleibt das System stabil.
Das Debuggen eingebetteter Logik ist ein Rätsel. Es erfordert Geduld, Präzision und ein tiefes Verständnis der Systemarchitektur. Durch die Einhaltung des hier dargestellten strukturierten Ansatzes können Entwickler Logikfehler effizient beheben und zuverlässige eingebettete Systeme aufbauen.
