











Les systèmes embarqués dépendent fortement d’un comportement déterministe. Lorsqu’un dispositif fonctionne, il doit réagir de manière prévisible aux entrées dans des conditions spécifiques. Les diagrammes de machines à états, souvent intégrés au langage de modélisation unifié (UML), servent de plan directeur pour ce comportement. Toutefois, c’est lors de la traduction d’un diagramme en code que les erreurs se cachent souvent. Les erreurs logiques dans les machines à états finis (FSM) peuvent entraîner des blocages du système, des redémarrages inattendus ou des risques de sécurité. 🚨
Ce guide propose une approche structurée pour identifier et résoudre les erreurs logiques dans les conceptions de machines à états. En comprenant les subtilités des transitions d’état, des conditions de garde et des structures hiérarchiques, les développeurs peuvent s’assurer que leur logiciel embarqué se comporte comme prévu.
🧩 Comprendre la complexité des FSM
Une machine à états définit les états possibles d’un système et la manière dont il passe d’un état à un autre. Dans les contextes embarqués, cela implique souvent des interactions matérielles, des temporisateurs et des interruptions externes. Contrairement au code procédural simple, les machines à états conservent un contexte. Si ce contexte est perdu ou corrompu, la logique échoue.
Les scénarios courants où les FSM sont essentiels incluent :
- Protocoles de communication (par exemple, gestion des états UART, SPI, I2C)
- Navigation dans l’interface utilisateur (par exemple, appuis sur boutons, transitions d’écran)
- Modes de gestion de l’alimentation (par exemple, veille, actif, veille active)
- Séquences de contrôle de moteur (par exemple, démarrage, fonctionnement, arrêt, erreur)
Lors du dépannage, il est essentiel de distinguer les bogues d’implémentation des défauts de conception. Un défaut de conception existe lorsque le diagramme lui-même ne couvre pas un scénario valide. Un bogue d’implémentation survient lorsque le code ne suit pas le diagramme.
⚠️ Erreurs logiques courantes dans les machines à états embarquées
Le débogage de la logique d’état exige une grande attention aux détails. Certaines catégories d’erreurs reviennent fréquemment. Reconnaître ces schémas accélère le processus de résolution.
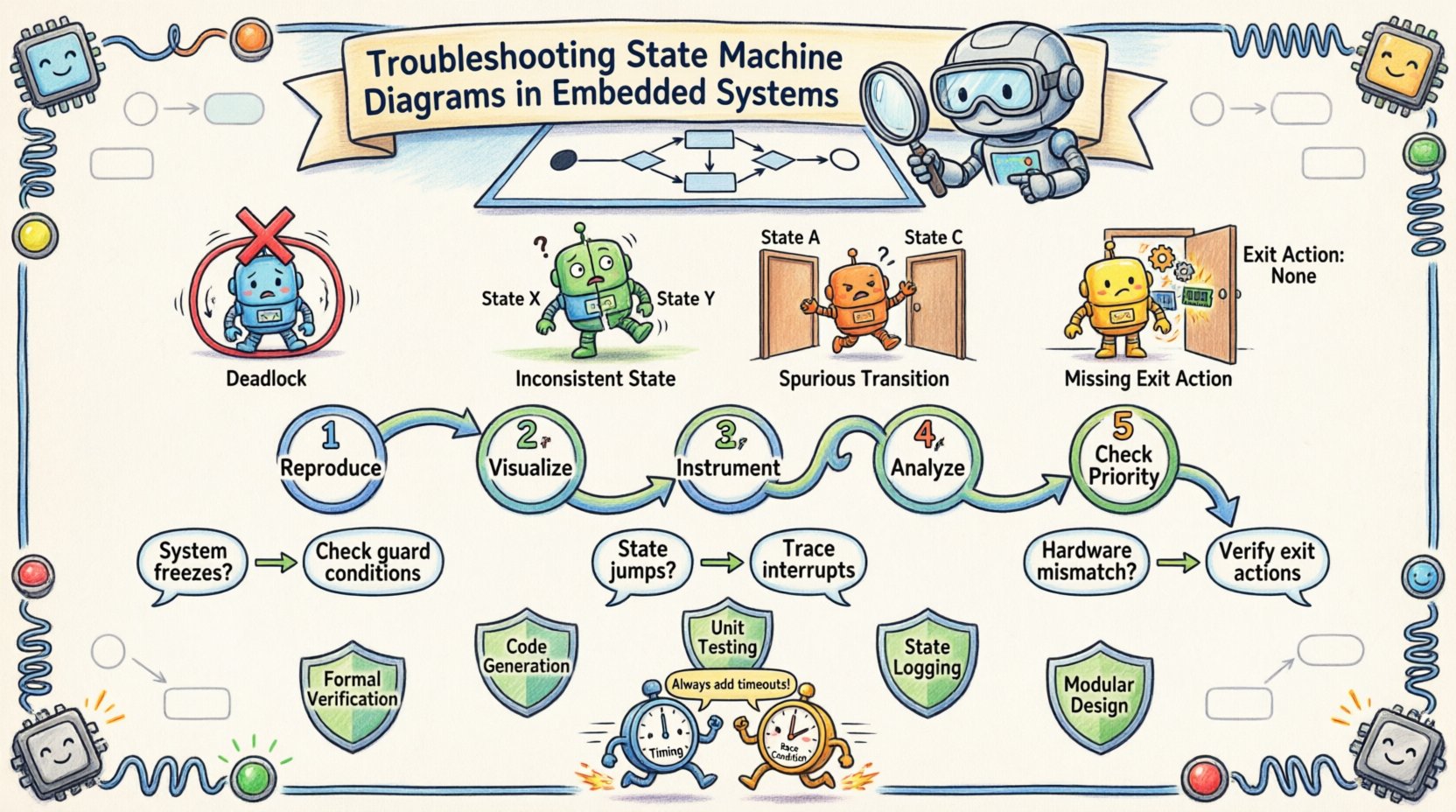
1. Le scénario de blocage
Un blocage se produit lorsque le système entre dans un état où aucune transition n’est possible, tout en n’étant pas dans un état terminal ou d’erreur. Le processeur reste inactif, en attente d’un événement qui n’arrivera jamais. Cela est souvent dû à :
- Absence de transitions par défaut (boucles sur soi-même) pour les événements non traités.
- Conditions de garde toujours fausses.
- Logique qui efface un indicateur d’événement avant que la machine à états ne le vérifie.
2. Transitions erronées
Les transitions erronées surviennent lorsque le système passe à un état qu’il ne devrait pas. Cela provient généralement de :
- Plusieurs événements déclenchant le même chemin de transition sans exclusion appropriée.
- Gestion incorrecte des files d’événements où un ancien événement déclenche un nouvel état.
- États concurrents qui ne sont pas correctement synchronisés.
3. États incohérents
Cela se produit lorsque les variables internes ne correspondent pas à l’état actuel de la machine. Par exemple, un moteur pourrait être dans l’état « En marche » sur le diagramme, mais le registre matériel indique « Arrêté ». Cette désynchronisation crée de la confusion pour les transitions ultérieures.
4. L’action de sortie manquante
Dans les machines complexes, quitter un état nécessite souvent une opération de nettoyage. Si l’action de sortie est omise dans le code mais présente dans la conception, des ressources (comme la mémoire ou les verrous) restent allouées. Avec le temps, cela entraîne une épuisement des ressources.
📊 Types d’erreurs vs. symptômes
Reportez-vous au tableau ci-dessous pour associer le comportement observé à des causes potentielles.
| Symptôme observé | Cause racine potentielle | Focus du diagnostic |
|---|---|---|
| Le système se fige à une entrée spécifique | Bloquage ou transition manquante | Vérifiez la file d’événements et les conditions de garde |
| L’état saute de manière inattendue | Transition erronée ou condition de course | Suivez le timing des interruptions et les drapeaux d’événements |
| Le matériel ne correspond pas à l’état | Action de sortie manquante ou mise à jour | Vérifiez les écritures dans les registres matériels à la sortie |
| Défaillances intermittentes sous charge | Problème de synchronisation ou condition de course | Analysez l’utilisation de la pile et les intervalles des temporisateurs |
| Le système démarre dans un état incorrect | Erreur d’initialisation | Vérifiez le gestionnaire de réinitialisation et l’état par défaut |
🔍 Flux de diagnostic étape par étape
Lorsque des erreurs logiques apparaissent, une approche systématique évite le gaspillage de temps. Ne devinez pas ; mesurez.
1. Reproduisez le problème
Assurez-vous que l’erreur est reproductible. Si le problème est intermittent, essayez d’isoler les conditions. Documentez la séquence des événements menant à l’échec. Une machine à états est déterministe ; si vous déclenchez la même séquence, vous devriez obtenir le même résultat.
2. Visualisez le flux
Ouvrez le diagramme UML. Suivez le chemin visuellement. Mettez en évidence l’état de départ et l’état cible. Recherchez des lacunes dans le diagramme. Le diagramme prend-il en compte chaque entrée possible dans chaque état ? Si une entrée n’est pas dessinée, le code pourrait la négliger ou la traiter incorrectement.
3. Instrumentez le code
Ajoutez des journaux aux points de transition clés. Cela ne nécessite pas d’outils coûteux. Des instructions d’affichage simples ou la commutation de broches GPIO peuvent révéler l’état du système en temps réel. Journalisez :
- ID de l’état actuel
- Événement déclencheur
- Évaluation de la condition de garde
- État cible
4. Analysez l’entrée et la sortie de l’état
Vérifiez que les actions d’entrée et de sortie sont déclenchées. Souvent, la transition a lieu, mais les effets secondaires (comme mettre une broche à haut) ne se produisent pas. Assurez-vous que la logique de la machine à états met à jour le matériel immédiatement à l’entrée.
5. Vérifiez la priorisation des événements
Si plusieurs événements se produisent simultanément, lequel a la priorité ? Le code doit définir une priorité claire. Si le code donne la priorité à l’Événement A mais que la conception s’attend à l’Événement B, la logique dérivera.
🧠 Approfondissement : Conditions de garde et événements de déclenchement
Les conditions de garde sont des expressions booléennes qui doivent être vraies pour qu’une transition ait lieu. Elles sont les portes logiques de la machine à états. Les erreurs ici sont subtiles, car le chemin de transition existe, mais la condition l’empêche.
Péchés courants des conditions de garde
- Portée des variables : La variable utilisée dans la condition de garde pourrait ne pas être mise à jour au moment attendu. Si un indicateur est défini dans une interruption mais lu dans la boucle principale, des problèmes de synchronisation surviennent.
- Négation logique : Une simple faute de frappe, comme utiliser “
!=au lieu de “==, peut inverser toute la logique. - Effets secondaires : Les conditions de garde doivent généralement être en lecture seule. Si une condition de garde modifie une variable globale, elle crée des changements d’état cachés difficiles à suivre.
Subtilités de la gestion des événements
Les événements sont les déclencheurs. Ils peuvent être :
- Signaux : Entrées asynchrones (par exemple, pression d’un bouton).
- Horloges : Entrées périodiques (par exemple, impulsion du watchdog).
- Erreurs : Entrées exceptionnelles (par exemple, erreur de CRC).
Assurez-vous que la source de l’événement est effacée après traitement. Si un indicateur d’événement reste activé, la machine à états pourrait traiter le même événement deux fois, provoquant une transition erronée.
🏗️ Gestion des états hiérarchiques et de l’héritage
Les systèmes complexes utilisent des états hiérarchiques pour réduire le brouillard du diagramme. Un état parent contient des états enfants. Les transitions peuvent avoir lieu au niveau du parent, affectant tous les enfants.
Problèmes liés à l’héritage
Lors du débogage des états hiérarchiques, des confusions surviennent souvent quant à l’emplacement réel de l’état.
- Transitions implicites : Passer d’un état enfant à un état frère exige souvent de quitter l’état parent. Assurez-vous que les actions de sortie de l’état parent sont exécutées correctement.
- Points d’entrée par défaut : Lorsqu’un état parent est entré, quel état enfant est actif ? Si l’état enfant par défaut n’est pas défini, le système peut rester dans un état indéfini.
- Transitions locales versus globales : Une transition définie sur un état enfant peut être déclenchée par un événement géré par l’état parent. Comprenez la portée de cet événement.
Meilleures pratiques pour la hiérarchie
- Minimisez la profondeur d’imbrication. Les hiérarchies profondes sont difficiles à suivre.
- Utilisez des états par défaut explicites pour tous les états composés.
- Documentez clairement le comportement des actions de sortie de l’état parent.
⏱️ Temps et conditions de course
Les systèmes embarqués fonctionnent en temps réel. Les machines à états ne sont pas immunisées contre les problèmes de temporisation. Les conditions de course surviennent lorsque le résultat dépend du décalage temporel relatif des événements.
Interruption versus boucle principale
Souvent, les événements d’état sont générés dans une routine de service d’interruption (ISR), mais traités dans la boucle principale. Si la boucle principale est lente, les événements peuvent s’accumuler. Si l’ISR efface un indicateur avant que la boucle principale ne le vérifie, les données sont perdues.
Déblocage des entrées
Les boutons physiques rebondissent. Si la machine à états interprète une pression unique comme plusieurs pressions, elle parcourra incorrectement le diagramme d’états. Implémentez une logique de déblocage à l’intérieur de la machine à états (par exemple, un état « Attendre ») plutôt que de vous fier uniquement au matériel.
Délais d’attente
Chaque état qui attend une entrée externe doit disposer d’un délai d’attente. Si un événement attendu ne parvient pas dans un délai spécifié, le système doit passer à un état d’erreur ou de récupération. Cela évite le scénario d’interblocage mentionné précédemment.
🛡️ Stratégies de prévention pour une conception robuste
Corriger les erreurs est réactif. Concevoir pour les éviter est proactif. Les stratégies suivantes réduisent la probabilité d’erreurs logiques dans les projets futurs.
- Vérification formelle : Là où c’est possible, utilisez des méthodes formelles pour vérifier la accessibilité des états. Cela garantit que chaque état est accessible et qu’aucun blocage mortel n’existe.
- Génération de code : Générez du code à partir du modèle du diagramme d’états. Cela réduit l’écart entre la conception et l’implémentation, minimisant les erreurs humaines.
- Tests unitaires : Traitez la machine à états comme tout autre module. Écrivez des tests pour chaque état et chaque transition. Couvrez à la fois les chemins de succès et les chemins d’erreur.
- Journalisation des états : Incluez un journalisateur d’états dans le firmware. Sur le terrain, ces données peuvent être analysées pour reproduire les problèmes sans accès physique.
- Conception modulaire : Divisez les grandes machines à états en sous-machines plus petites et interagissant. Cela simplifie le modèle mental et isole les pannes.
🧰 Outils et techniques d’analyse
Bien que les outils logiciels spécifiques varient, les techniques d’analyse fondamentales restent constantes.
Analyse statique
Exécutez une analyse statique sur le code source. Recherchez :
- Blocs de code inatteignables.
- Variables inutilisées dans la logique d’état.
- Masquage de variables qui pourrait cacher des valeurs d’état.
Analyse dynamique
Utilisez un débogueur pour avancer pas à pas à travers les transitions.
- Définissez des points d’arrêt sur les fonctions d’entrée et de sortie d’état.
- Surveillez étroitement la variable d’état pendant l’exécution.
- Surveillez la file d’entrée pour vous assurer que les événements sont traités dans l’ordre.
Tests en boucle matérielle
Testez la machine à états avec des signaux réels de matériel. Les entrées simulées manquent souvent des caractéristiques électriques telles que le bruit ou la latence, qui déclenchent des erreurs logiques.
📝 Réflexions finales sur la maintenance
Maintenir une machine à états exige de la discipline. À mesure que les exigences évoluent, le diagramme doit être mis à jour. Si le diagramme n’est pas mis à jour en parallèle avec le code, la dette technique s’accumule rapidement. Une machine à états qui ne correspond plus à son diagramme est une bombe à retardement.
Les revues régulières de la logique d’état sont essentielles. Lorsqu’une nouvelle fonctionnalité est ajoutée, comparez-la aux transitions existantes. Y a-t-il un conflit avec un chemin existant ? Introduit-elle un nouveau blocage ? En maintenant la documentation de conception à jour et le code aligné, le système reste stable.
Déboguer la logique embarquée est un puzzle. Cela exige de la patience, de la précision et une compréhension approfondie de l’architecture du système. En suivant l’approche structurée décrite ici, les développeurs peuvent résoudre efficacement les erreurs logiques et construire des systèmes embarqués fiables.
