Introduction
Le paysage de l’architecture logicielle connaît un changement majeur. Pendant des décennies, la fondation de toute application robuste — la base de données — a été conçue grâce à un travail rigoureux et manuel. Ce processus, connu sous le nom de Évolution de la modélisation des bases de données, est désormais en transition de l’ère des plans manuels vers une nouvelle ère de Architecture pilotée par l’IA.
Traditionnellement, la conception des structures de données exigeait une expertise approfondie, des outils isolés et un investissement important en temps. Il s’agissait d’un processus à fort friction sujet aux erreurs humaines, aux redondances et à la dette architecturale. Toutefois, des innovations telles queVisual Paradigm’s DB Modeler AI ont bouleversé cet état de fait. En introduisant un workflow intelligent et guidé workflow en 7 étapes, cette technologie exploite l’intelligence artificielle générative pour transformer des descriptions en langage naturel en schémas de base de données entièrement normalisés et prêts à être déployés en production.
Ce guide complet explore cette évolution, mettant en évidence les différences marquées entre les méthodes anciennes et les capacités modernes de l’IA. Nous allons passer en revue l’application pratique de ces outils à l’aide d’un scénario classique librairie en ligne scénario, démontrant comment l’IA élimine les points de douleur traditionnels et accélère la conception professionnelle des bases de données.
La lutte traditionnelle : contraintes manuelles et forte friction
À l’époque pré-IA, la modélisation des bases de données était considérée comme un métier exigeant, réservé aux spécialistes. Le processus était chargé de défis qui ralentissaient souvent les cycles de développement et introduisaient des vulnérabilités.
Le workflow ancien
- Le canevas vierge :Les concepteurs commençaient par des espaces de travail vides dans des outils comme ER/Studio, Lucidchart ou même sur papier à main. Il n’y avait aucune base de départ ; chaque entité devait être conçue de zéro.
- Identification manuelle : L’architecte devait identifier manuellement entités, attributs, relations, clés primaires (PK), et clés étrangères (FK). Cela exigeait un modèle mental parfait de la logique métier avant de tracer la moindre ligne.
- Le problème de la normalisation : Passer d’un brouillon à un schéma déployé implique Normalisation (1NF → 2NF → 3NF). Ce processus recherche les redondances, les dépendances partielles et les dépendances transitives. Traditionnellement, cela exigeait une analyse manuelle fastidieuse, très sujette à des oublis et à des erreurs humaines.
- Outils passifs : Les outils anciens agissaient comme des tableaux numériques. Ils ne proposaient aucune suggestion intelligente, aucune transition automatique entre les modèles conceptuels et logiques, et aucune validation au-delà du contrôle syntaxique de base.
- Silos de test : La validation nécessitait la mise en place d’environnements de base de données locaux (par exemple, PostgreSQL, MySQL), l’écriture manuelle de
INSERTscripts, et espérer que les requêtes révéleraient des problèmes d’intégrité.
Le résultat de cette approche manuelle était souvent un endettement architectural important, des cycles d’itération longs et une courbe d’apprentissage abrupte qui excluait les non-experts, comme les gestionnaires de produits ou les étudiants, du processus de conception.
Le changement de paradigme alimenté par l’IA
DB Modeler AI, accessible viala plateforme en ligne de Visual Paradigm, représente un changement fondamental dans la manière dont nous abordons les données. Il agit non seulement comme un outil, mais comme un « copilote intelligent ». en utilisant Traitement automatique du langage naturel (NLP) et des connaissances domaines étendues, il interprète les exigences métier pour générer des modèles conformes aux normes.
Comparaison : Modélisation traditionnelle vs. modélisation pilotée par l’IA
Le tableau suivant décrit les principales différences opérationnelles entre l’approche manuelle traditionnelle et le flux de travail moderne piloté par l’IA.
| Fonctionnalité | Méthode manuelle traditionnelle | Méthode pilotée par l’IA (DB Modeler AI) |
|---|---|---|
| Mécanisme d’entrée | Glisser-déposer manuel ; définition explicite de chaque colonne. | Langage naturel (descriptions en anglais courant). |
| Vitesse | Jours ou semaines pour des schémas complexes. | Minutes de la conception à un schéma normalisé. |
| Normalisation | Analyse manuelle ; sujette aux erreurs humaines et aux oublis. | Guidage automatisé, étape par étape (1NF, 2NF, 3NF) avec explications. |
| Validation | Exige une configuration externe de la base de données et la rédaction manuelle de scripts. | Environnement SQL instantané dans le navigateur avec des données de test générées par l’IA. |
| Accessibilité | Exige une connaissance approfondie du SQL et de l’architecture. | Accessibles aux développeurs, chefs de projet, étudiants et architectes. |
| Qualité de sortie | Entièrement dépendante de l’expertise de l’utilisateur. | Standardisé, conforme aux meilleures pratiques, DDL prêt à être déployé en production. |
Le workflow guidé en 7 étapes
Visual ParadigmL’IA du modèleur de base de données de Visual Paradigm utilise un processus transparent en sept étapes qui guide l’utilisateur depuis une idée floue jusqu’à un schéma de base de données concret et testé.
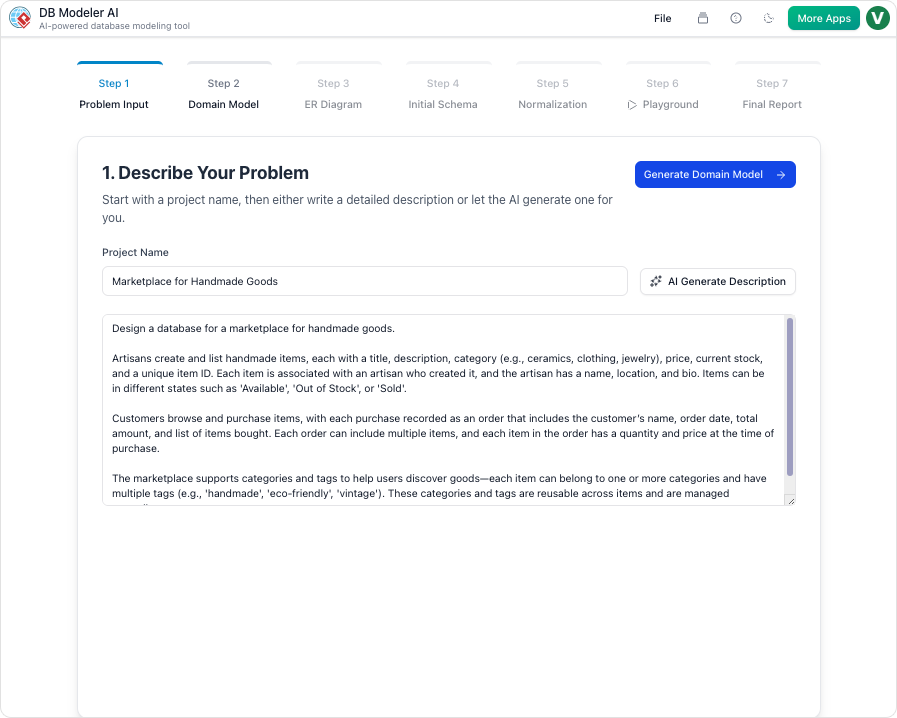
1. Entrée du problème
Le processus commence par une simple invite. Les utilisateurs décrivent leur application en langage courant. Par exemple :« Construire une base de données pour une librairie en ligne qui gère les livres, les auteurs, les clients, les commandes et permet le suivi des livraisons. » L’IA analyse ce texte pour extraire les exigences fondamentales.
2. Diagramme de classes du domaine
Avant de plonger dans les tables et les clés, l’IA génère une vue conceptuelle de haut niveau en utilisant la syntaxe PlantUML. Cela permet de visualiser de manière abstraite les objets et leurs relations, en s’assurant que la portée est correcte avant la mise en œuvre technique.
3. Génération du diagramme Entité-Relation
Le système passe automatiquement du modèle conceptuel à un modèle logique détailléDiagramme Entité-Relation (ERD). Il définit automatiquement les tables, les colonnes, les cardinalités, les clés primaires et les clés étrangères.
4. Génération du schéma initial
L’ERD est converti en langage de définition de données SQL (DDL). L’outil utilise généralement comme standard par défaut des normes largement utilisées comme PostgreSQL, garantissant la compatibilité avec les piles technologiques modernes.
5. Normalisation intelligente
C’est sans doute l’étape la plus critique. L’IA affine progressivement le schéma pour garantir l’intégrité des données :
- 1NF (Première forme normale) : Assure l’atomicité. Elle élimine les champs à valeurs multiples (par exemple, garantir qu’une cellule ne contient pas une liste séparée par des virgules d’auteurs).
- 2NF (Deuxième forme normale) : Élimine les dépendances partielles. Elle garantit que les attributs non clés dépendent de la clé primaire entière, souvent en divisant les tables (par exemple, séparer les détails de l’auteur du tableau Livre).
- 3NF (Troisième forme normale) : Élimine les dépendances transitives. Elle garantit que les colonnes dépendent uniquement de la clé primaire, et non d’autres colonnes non clés.
Crucialement, l’IA fournit des justifications éducatives pour chaque décision, en expliquant pourquoi une table a été divisée, ce qui en fait un outil d’apprentissage puissant.
6. Plateforme interactive
Au lieu de nécessiter un serveur local, l’outil propose un environnement SQL basé navigateur. Il remplit automatiquement le schéma avec des données d’exemple réalistes générées par l’IA. Cela permet de tester immédiatement les requêtes et les opérations CRUD.
7. Rapport final et export
Une fois validé, l’utilisateur peut générer un rapport de conception au format Markdown, exporter les scripts SQL et télécharger les diagrammes au format PDF ou JSON. Cela constitue une « source unique de vérité » pour l’équipe de développement.
Exemple pratique : conception d’une librairie en ligne
Pour démontrer la puissance de ce flux de travail, appliquons-le au librairie en lignescénario mentionné dans le matériel source.
Étape 1 : La requête
Nous saisissons la demande suivante : « J’ai besoin d’un système pour une librairie en ligne afin de gérer les livres (avec titres, auteurs, prix, catégories, ISBN), les clients (nom, courriel, adresse), les commandes (date, statut, total) et les articles de commande. Les clients naviguent par auteur/catégorie, passent des commandes et suivent leurs livraisons. »
Étape 2 et 3 : Visualisation de la structure
L’IA crée instantanément un diagramme de domaine Diagramme de classes suivi d’un Diagramme Entité-Relation. Il identifie qu’un Client a un 1:N relation avec Commandes, et que Livres ont une N:M (relation plusieurs-à-plusieurs) avec Commandes, nécessitant une table intermédiaire OrderItem table.
Étape 4 et 5 : Affinement et normalisation
Initialement, le schéma pourrait stocker directement le nom de l’auteur à l’intérieur de la Livres table. L’IA identifie cela comme une violation de la conception optimale de la base de données.
- Action : L’IA extrait
Auteurdans sa propre table. - Résultat : La
Livrestable contient maintenant unauthor_idclé étrangère. - Avantage : Cela élimine la redondance ; si un auteur change son nom, il n’est nécessaire de le mettre à jour qu’en un seul endroit.
Étape 6 : Test dans l’outil d’expérimentation
Avec le schéma généré, l’IA alimente la base de données avec des données réalistes (par exemple, « Le grand Gatsby » par F. Scott Fitzgerald). Nous pouvons immédiatement exécuter une requête de test pour valider la structure :
SELECT b.title, a.name
FROM livres b
JOINDRE auteurs a ON b.auteur_id = a.id
OÙ b.categorie = 'Fiction';Si la requête retourne les résultats attendus, le design est validé instantanément.
Conclusion : Réduction de la dette architecturale
La transition des plans manuels vers architecture pilotée par l’IA via des outils commeVisual Paradigm DB Modeler IAdémocratise la conception de bases de données de haute qualité. Elle comble l’écart entre les exigences conceptuelles métier et la mise en œuvre technique.
Ce qui nécessitait autrefois des semaines de travail d’experts et comportait le risque d’erreurs coûteuses peut maintenant être accompli en quelques minutes. Grâce à des fonctionnalités intégrées d’éducation, de validation et de collaboration, cette technologie permet aux étudiants, aux gestionnaires de produits et aux développeurs de concevoir des architectures de données plus rapides et plus fiables. À mesure que nous progressons, l’intégration de l’IA à l’étape fondamentale de modélisation des bases de données devrait devenir la norme pour réduire la dette architecturale et accélérer l’innovation.
