परिचय
सॉफ्टवेयर आर्किटेक्चर का माहौल एक भूकंपीय बदलाव के माध्यम से गुजर रहा है। दशकों तक, किसी भी विश्वसनीय एप्लिकेशन का आधार—डेटाबेस—को कठोर, हाथ से काम करके बनाया गया था। इस प्रक्रिया को जाना जाता है डेटाबेस मॉडलिंग का विकास, अब मैनुअल ब्लूप्रिंट्स के युग से एक नए युग में बदल रहा है एआई-चालित आर्किटेक्चर.
पारंपरिक रूप से, डेटा संरचनाओं को डिज़ाइन करने के लिए गहन विशेषज्ञता, अलग-अलग उपकरणों और महत्वपूर्ण समय निवेश की आवश्यकता होती थी। यह एक उच्च-घर्षण वाली प्रक्रिया थी जिसमें मानव त्रुटियों, अतिरिक्तता और आर्किटेक्चरल देनदारी का खतरा रहता था। हालांकि, ऐसे नवाचार जैसेविजुअल पैराडाइम का डीबी मॉडेलर एआई ने इस स्थिति को बदल दिया है। एक बुद्धिमान, मार्गदर्शित 7-चरण की प्रक्रिया, यह तकनीक जनरेटिव एआई का उपयोग करके सामान्य अंग्रेजी वर्णन को पूरी तरह से नॉर्मलाइज्ड, उत्पादन-तैयार डेटाबेस स्कीमा में बदल देती है।
यह व्यापक गाइड इस विकास का अध्ययन करती है, पुरानी विधियों और आधुनिक एआई क्षमताओं के बीच तीव्र अंतर पर बल देती है। हम एक पारंपरिक ऑनलाइन बुकस्टोरपरिदृश्य का उपयोग करके यह दिखाते हैं कि एआई पारंपरिक दर्द के बिंदुओं को कैसे दूर करती है और पेशेवर डेटाबेस डिज़ाइन को कैसे तेज करती है।
पारंपरिक संघर्ष: हाथ से नियंत्रित बाधाएं और उच्च घर्षण
एआई के पहले के युग में, डेटाबेस मॉडलिंग को विशेषज्ञों के लिए आरक्षित एक श्रम-ग्रस्त कला माना जाता था। इस प्रक्रिया में चुनौतियां भरी होती थीं जो अक्सर विकास चक्र को धीमा कर देती थीं और लचीलापन लाती थीं।
पुरानी प्रक्रिया
- खाली कैनवास: डिज़ाइनर एर/स्टूडियो, लुसिडचार्ट या यहां तक कि भौतिक पेन और कागज के साथ खाली कार्यक्षेत्र से शुरुआत करते थे। कोई शुरुआती लाभ नहीं था; प्रत्येक एंटिटी को शुरुआत से ही विचार करना पड़ता था।
- हाथ से पहचान: आर्किटेक्ट को हाथ से पहचानना पड़ता था एंटिटीज, लक्षण, संबंध, प्राथमिक कुंजियां (पीकेएस), और विदेशी कुंजियाँ (FKs). एक भी रेखा खींचने से पहले व्यापार तर्क का एक सही मानसिक मॉडल आवश्यक था।
- नॉर्मलाइजेशन की परेशानी: एक खराब ड्राफ्ट से डेप्लॉय किए गए स्कीमा तक जाने में शामिल हैनॉर्मलाइजेशन (1NF → 2NF → 3NF). इस प्रक्रिया में अतिरिक्तता, आंशिक निर्भरता और स्थानांतरित निर्भरता की तलाश की जाती है। पारंपरिक रूप से, इसके लिए ध्यान से हाथ से विश्लेषण की आवश्यकता होती थी, जो बहुत अधिक लापरवाही और मानव त्रुटि के लिए अधिक संवेदनशील थी।
- निष्क्रिय उपकरण: पुराने उपकरण डिजिटल ड्राइंग बोर्ड के रूप में कार्य करते थे। इनमें कोई बुद्धिमान सुझाव नहीं थे, अवधारणात्मक और तार्किक मॉडल के बीच कोई स्वचालित संक्रमण नहीं था, और बुनियादी सिंटैक्स जांच के अलावा कोई मान्यता नहीं थी।
- परीक्षण के अलग-अलग ढांचे: मान्यता के लिए स्थानीय डेटाबेस परिवेश सेट करने की आवश्यकता होती थी (जैसे: PostgreSQL, MySQL), हाथ से लिखना
INSERTस्क्रिप्ट्स, और आशा करना कि प्रश्नों से अखंडता की समस्याएं प्रकट हों।
इस हाथ से तरीके का परिणाम अक्सर महत्वपूर्ण संरचनात्मक ऋण, लंबे इटरेशन साइकिल और एक तीखा सीखने का वक्र था, जिसने उत्पाद प्रबंधकों या छात्रों जैसे अनुभवहीन लोगों को डिजाइन प्रक्रिया से बाहर रखा।
आईएआई-संचालित परंपरा में परिवर्तन
DB मॉडलर आईएआई, द्वारा सुलभविजुअल पैराडाइम का ऑनलाइन प्लेटफॉर्म, डेटा के प्रति हमारे दृष्टिकोण में एक मौलिक परिवर्तन का प्रतिनिधित्व करता है। यह केवल एक उपकरण के रूप में नहीं, बल्कि एक “बुद्धिमान सह-चालक” के रूप में कार्य करता है। उपयोग करते हुएप्राकृतिक भाषा प्रसंस्करण (NLP) और व्यापक क्षेत्र ज्ञान, यह व्यापार आवश्यकताओं की व्याख्या करता है और मानकों के अनुरूप मॉडल उत्पन्न करता है।
तुलना: पारंपरिक बनावट बनाम आईएआई-संचालित मॉडलिंग
निम्नलिखित तालिका पारंपरिक हाथ से तरीके और आधुनिक आईएआई-संचालित वर्कफ्लो के बीच मुख्य संचालन अंतरों का वर्णन करती है।
| विशेषता | पारंपरिक हाथ से तरीका | आईएआई-संचालित तरीका (DB मॉडलर आईएआई) |
|---|---|---|
| इनपुट तंत्र | हाथ से ड्रैग-एंड-ड्रॉप; प्रत्येक कॉलम की स्पष्ट परिभाषा। | प्राकृतिक भाषा (साधारण अंग्रेजी वर्णन)। |
| गति | जटिल स्कीमा के लिए दिन या हफ्ते। | अवधारणा से सामान्यीकृत स्कीमा तक मिनट। |
| सामान्यीकरण | हाथ से विश्लेषण; मानव त्रुटि और लापरवाही के लिए अधिक संवेदनशील। | स्वचालित, चरण-दर-चरण मार्गदर्शन (1NF, 2NF, 3NF) स्पष्टीकरण के साथ। |
| सत्यापन | बाहरी डीबी सेटअप और हाथ से स्क्रिप्ट लिखने की आवश्यकता होती है। | तत्काल, ब्राउज़र में SQL प्लेग्राउंड जिसमें AI द्वारा उत्पन्न परीक्षण डेटा है। |
| पहुंच | गहन SQL/आर्किटेक्चर ज्ञान की आवश्यकता होती है। | डेवलपर्स, पीएम, छात्रों और आर्किटेक्ट्स के लिए सुलभ। |
| आउटपुट गुणवत्ता | उपयोगकर्ता के विशेषज्ञता पर पूरी तरह निर्भर। | मानकीकृत, बेस्ट-प्रैक्टिस के अनुरूप, उत्पादन-तैयार DDL। |
7-चरण गाइडेड वर्कफ्लो
विजुअल पैराडाइम‘s डीबी मॉडेलर एआई एक पारदर्शी, सात चरणों की प्रक्रिया का उपयोग करता है जो उपयोगकर्ता को एक अस्पष्ट विचार से एक ठोस, परीक्षण किए गए डेटाबेस स्कीमा तक गाइड करता है।
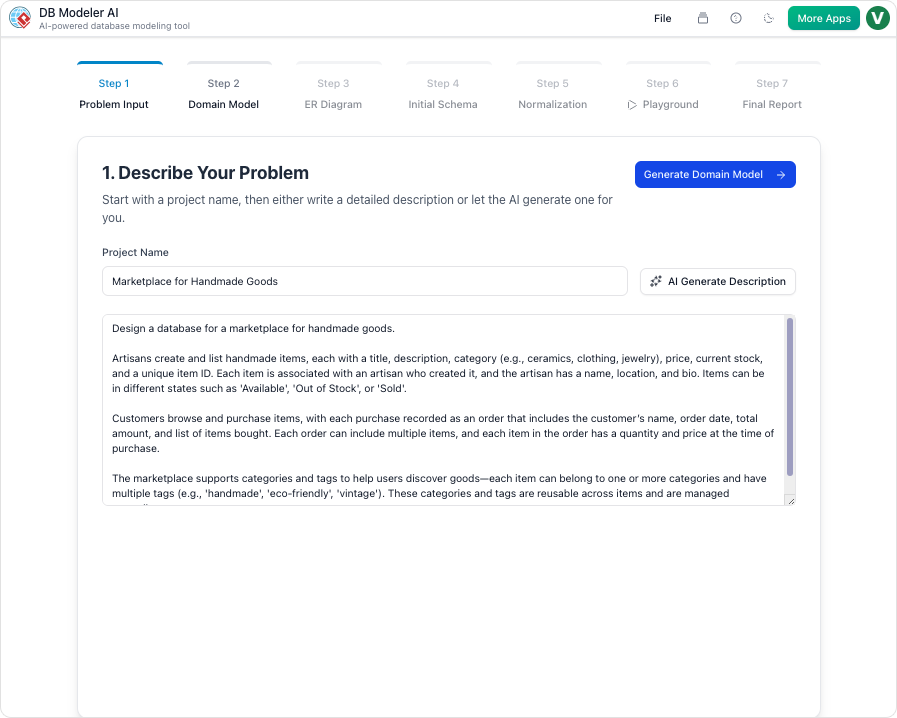
1. समस्या इनपुट
प्रक्रिया एक सरल प्रॉम्प्ट के साथ शुरू होती है। उपयोगकर्ता अपने एप्लिकेशन का वर्णन सरल अंग्रेजी में करते हैं। उदाहरण के लिए: “एक ऑनलाइन पुस्तकालय के लिए एक डेटाबेस बनाएं जो पुस्तकों, लेखकों, ग्राहकों, आदेशों के प्रबंधन करता है और शिपमेंट के ट्रैकिंग की अनुमति देता है।” एआई इस टेक्स्ट का विश्लेषण करता है ताकि मुख्य आवश्यकताएं निकाली जा सकें।
2. डोमेन क्लास डायग्राम
तालिकाओं और कुंजियों में डूबने से पहले, एआई प्लांटयूएमएल सिंटैक्स का उपयोग करके एक उच्च स्तर का संकल्पनात्मक दृश्य बनाता है। यह वस्तुओं और उनके संबंधों को एक सारांश रूप में दिखाने में मदद करता है, ताकि तकनीकी कार्यान्वयन से पहले स्कोप सही हो।
3. ईआर डायग्राम उत्पादन
प्रणाली स्वचालित रूप से संकल्पनात्मक मॉडल से विस्तृत तार्किक एंटिटी-रिलेशनशिप डायग्राम (ईआरडी)। यह स्वचालित रूप से तालिकाओं, कॉलम, कार्डिनैलिटी, पीके और एफके को परिभाषित करता है।
4. प्रारंभिक स्कीमा उत्पादन
ईआरडी को SQL डेटा परिभाषा भाषा (डीडीएल) में बदल दिया जाता है। टूल आमतौर पर पोस्टग्रेसक्वल जैसे व्यापक रूप से उपयोग किए जाने वाले मानकों पर डिफ़ॉल्ट होता है, जिससे आधुनिक तकनीक स्टैक के साथ संगतता सुनिश्चित होती है।
5. बुद्धिमान सामान्यीकरण
यह निश्चित रूप से सबसे महत्वपूर्ण चरण है। एआई स्कीमा को डेटा अखंडता सुनिश्चित करने के लिए धीरे-धीरे सुधारता है:
- 1NF (प्रथम सामान्य रूप): परमाणुता सुनिश्चित करता है। यह बहु-मान वाले क्षेत्रों को दूर करता है (उदाहरण के लिए, यह सुनिश्चित करता है कि कोई सेल में लेखकों की कोमा-अलग लिस्ट नहीं होती है)।
- 2NF (द्वितीय सामान्य रूप): आंशिक निर्भरता को हटाता है। यह सुनिश्चित करता है कि गैर-कुंजी विशेषताएँ पूर्ण मुख्य कुंजी पर निर्भर हों, आमतौर पर तालिकाओं को विभाजित करके (उदाहरण के लिए, लेखक विवरण को पुस्तक तालिका से अलग करके)।
- 3NF (तृतीय सामान्य रूप): स्थानांतरित निर्भरता को दूर करता है। यह सुनिश्चित करता है कि कॉलम केवल मुख्य कुंजी पर निर्भर हों, अन्य गैर-कुंजी कॉलम पर नहीं।
महत्वपूर्ण बात यह है कि AI प्रदान करता हैशैक्षिक तर्क हर निर्णय के लिए, व्याख्या करता हैक्यों एक तालिका को विभाजित किया गया था, जिससे यह एक शक्तिशाली सीखने का साधन बन जाता है।
6. इंटरैक्टिव प्लेग्राउंड
स्थानीय सर्वर की आवश्यकता नहीं होती है, बल्कि उपकरण ब्राउज़र-आधारित SQL पर्यावरण प्रदान करता है। यह स्वचालित रूप से वास्तविक, AI-जनित नमूना डेटा के साथ स्कीमा को भरता है। इससे प्रश्नों और CRUD ऑपरेशन का तुरंत परीक्षण संभव होता है।
7. अंतिम रिपोर्ट और निर्यात
जब वैधता प्राप्त हो जाती है, तो उपयोगकर्ता मार्कडाउन डिज़ाइन रिपोर्ट बना सकता है, SQL स्क्रिप्ट्स निर्यात कर सकता है, और PDF या JSON प्रारूप में आरेख डाउनलोड कर सकता है। यह विकास टीम के लिए एक “एकल स्रोत सत्य” के रूप में कार्य करता है।
व्यावहारिक उदाहरण: ऑनलाइन पुस्तकालय का डिज़ाइन
इस प्रक्रिया की शक्ति को दिखाने के लिए, आइए इसका उपयोग स्रोत सामग्री में उल्लिखितऑनलाइन पुस्तकालयपरिदृश्य पर लागू करें।
चरण 1: प्रॉम्प्ट
हम निम्नलिखित आवश्यकता दर्ज करते हैं:“मुझे एक ऑनलाइन पुस्तकालय के लिए एक प्रणाली की आवश्यकता है जो पुस्तकों (शीर्षक, लेखक, मूल्य, श्रेणियाँ, ISBN), ग्राहकों (नाम, ईमेल, पता), आदेशों (तिथि, स्थिति, कुल राशि), और आदेश आइटम का प्रबंधन करे। ग्राहक लेखक/श्रेणी के आधार पर ब्राउज़ करते हैं, आदेश देते हैं और शिपमेंट का ट्रैक रखते हैं।”
चरण 2 और 3: संरचना का दृश्यीकरण
AI तुरंत एक डोमेनक्लास आरेखके बाद एकER आरेख। यह पहचानता है कि एकग्राहकके पास एक1:N संबंध के साथ आदेश, और वह पुस्तकें के साथ एक है N:M (बहुत-से-से-बहुत-से) संबंध के साथ आदेश, एक बीच के तत्व की आवश्यकता होती है आदेश आइटम तालिका।
चरण 4 और 5: सुधार और सामान्यीकरण
प्रारंभ में, स्कीमा लेखक के नाम को सीधे अंदर संग्रहीत कर सकता है पुस्तकें तालिका। AI इसे आदर्श डेटाबेस डिजाइन के उल्लंघन के रूप में पहचानता है।
- कार्रवाई: AI निकालता है
लेखकअपनी तालिका में। - परिणाम: द
पुस्तकेंतालिका अब एक हैलेखक_idविदेशी कुंजी। - लाभ: यह अतिरिक्तता को दूर करता है; यदि एक लेखक अपना नाम बदलता है, तो इसे केवल एक जगह अपडेट करने की आवश्यकता होती है।
चरण 6: प्लेग्राउंड में परीक्षण
स्कीमा उत्पन्न करने के बाद, AI डेटाबेस को वास्तविक डेटा (उदाहरण के लिए, “द ग्रेट गेट्सबी” एफ. स्कॉट फिट्जरॉल्ड द्वारा) के साथ बीजित करता है। हम तुरंत संरचना की पुष्टि करने के लिए एक परीक्षण क्वेरी चला सकते हैं:
SELECT b.title, a.name
FROM books b
JOIN authors a ON b.author_id = a.id
WHERE b.category = 'काल्पनिक';यदि प्रश्न प्रतीक्षित परिणाम लौटाता है, तो डिज़ाइन तुरंत सत्यापित हो जाता है।
निष्कर्ष: आर्किटेक्चरल देनदारी कम करना
हस्तलिखित ब्लूप्रिंट्स से संक्रमण करनाAI-चालित आर्किटेक्चरजैसे उपकरणों के माध्यम सेविजुअल पैराडाइग्म डीबी मॉडेलर एआईउच्च गुणवत्ता वाले डेटाबेस डिज़ाइन को लोकतंत्रीकृत करता है। यह अवधारणात्मक व्यावसायिक आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के अंतर को पार करता है।
जो कभी विशेषज्ञ श्रम के सप्ताहों की आवश्यकता करता था और महंगी त्रुटियों के जोखिम के साथ आता था, अब मिनटों में पूरा किया जा सकता है। अंतर्निहित शिक्षा, सत्यापन और सहयोग विशेषताओं के साथ, यह तकनीक छात्रों, उत्पाद प्रबंधकों और विकासकर्मियों को तेजी से, अधिक विश्वसनीय डेटा आर्किटेक्चर बनाने में सक्षम बनाती है। जैसे हम आगे बढ़ते हैं, डेटाबेस मॉडलिंग के आधारभूत चरण में AI को एकीकृत करना आर्किटेक्चरल देनदारी कम करने और नवाचार को तेजी से बढ़ावा देने के लिए मानक बनने की संभावना है।
