序論
ソフトウェアアーキテクチャのあり方は劇的な変化を迎えています。数十年にわたり、いかなる堅牢なアプリケーションの基盤となるデータベースは、厳密な手作業によって構想されてきました。このプロセスは「データベースモデリングの進化」と呼ばれ、今や手動の図面の時代から、新たな時代の「AI駆動型アーキテクチャ.
従来、データ構造の設計には深い専門知識、孤立したツール、そして大きな時間投資が必要でした。これは人為的ミスや重複、アーキテクチャ的負債を引き起こしやすい高摩擦プロセスでした。しかし、Visual ParadigmのDB Modeler AIといった革新がこの現状を覆しました。知能的でガイドされた「7段階ワークフロー」を導入することで、この技術は生成型AIを活用し、平易な英語の記述を完全正規化された、プロダクション対応のデータベーススキーマに変換します。
この包括的なガイドでは、伝統的な手法と現代のAI機能との間の顕著な違いを強調しつつ、この進化を検証します。古典的な「オンライン書店」のシナリオを用いて、これらのツールの実用的応用を紹介し、AIが従来の課題を解消し、プロフェッショナルなデータベース設計を加速する様子を示します。
伝統的な課題:手動による制約と高摩擦
AI以前の時代、データベースモデリングは専門家に限られた労働集約的な技術とされていました。このプロセスはしばしば開発サイクルを遅らせ、脆弱性を生じさせる多くの課題を抱えていました。
伝統的なワークフロー
- 白紙のキャンバス:デザイナーはER/StudioやLucidchart、あるいは物理的な鉛筆と紙など、空の作業スペースから始めました。出発点となる支援はなく、すべてのエンティティをゼロから構想しなければなりませんでした。
- 手動による識別:アーキテクトは手動で以下を特定しなければなりませんでした。エンティティ, 属性, 関係, 主キー(PK)、および外部キー (FK)これは、1本の線も引く前に、ビジネスロジックの完璧な精神的モデルを必要とした。
- 正規化の悩み:原稿からデプロイ可能なスキーマへ移行するには、正規化 (1NF → 2NF → 3NF)。このプロセスは重複、部分的依存、推移的依存を検出する。従来、この作業は細心の注意を要する手作業による分析を必要とし、見落としや人的ミスのリスクが非常に高かった。
- 受動的ツール:レガシーツールはデジタル図面板として機能していた。知的な提案はなく、概念モデルと論理モデル間の自動遷移もできず、基本的な構文チェックを超えた検証も提供しなかった。
- テストの孤立:検証にはローカルデータベース環境(例:PostgreSQL、MySQL)の構築が必要であり、手動で
INSERTスクリプトを書く必要があり、クエリが整合性の問題を明らかにすることを願った。
この手作業によるアプローチの結果、しばしば大きなアーキテクチャ的負債や長い反復サイクルが生じ、プロダクトマネージャーや学生のような専門家でない人々が設計プロセスから排除されるという厳しい学習曲線が生じた。
AI駆動のパラダイムシフト
DB Modeler AI、Visual Paradigmのオンラインプラットフォーム、データへのアプローチの根本的な変化を表している。単なるツールではなく、「知的なコ・パイロット」として機能する。自然言語処理 (NLP)および広範なドメイン知識を活用して、ビジネス要件を解釈し、標準準拠のモデルを生成する。
比較:従来型 vs. AI駆動型モデリング
以下の表は、従来の手作業アプローチと現代のAI駆動ワークフローの主な運用上の違いを示している。
| 機能 | 従来の手作業法 | AI駆動法 (DB Modeler AI) |
|---|---|---|
| 入力メカニズム | 手動によるドラッグアンドドロップ;すべてのカラムの明示的定義。 | 自然言語(平易な英語による記述)。 |
| スピード | 複雑なスキーマには数日から数週間を要する。 | コンセプトから正規化されたスキーマまで数分で完了。 |
| 正規化 | 手動での分析;人的な誤りや見落としのリスクがある。 | 自動化されたステップバイステップのガイド(1NF、2NF、3NF)、解説付き。 |
| 検証 | 外部のDB設定と手動でのスクリプト作成を必要とする。 | AI生成のテストデータを搭載した、ブラウザ内での即時SQL実行環境。 |
| アクセスのしやすさ | 深いSQL/アーキテクチャの知識を必要とする。 | 開発者、PM、学生、アーキテクトすべてが利用可能。 |
| 出力品質 | ユーザーの専門知識に完全に依存する。 | 標準化され、ベストプラクティス準拠で、本番環境対応のDDL。 |
7段階のガイド付きワークフロー
Visual ParadigmDB Modeler AIは、曖昧なアイデアから具体的で検証済みのデータベーススキーマへと導く、透明性のある7段階プロセスを活用している。
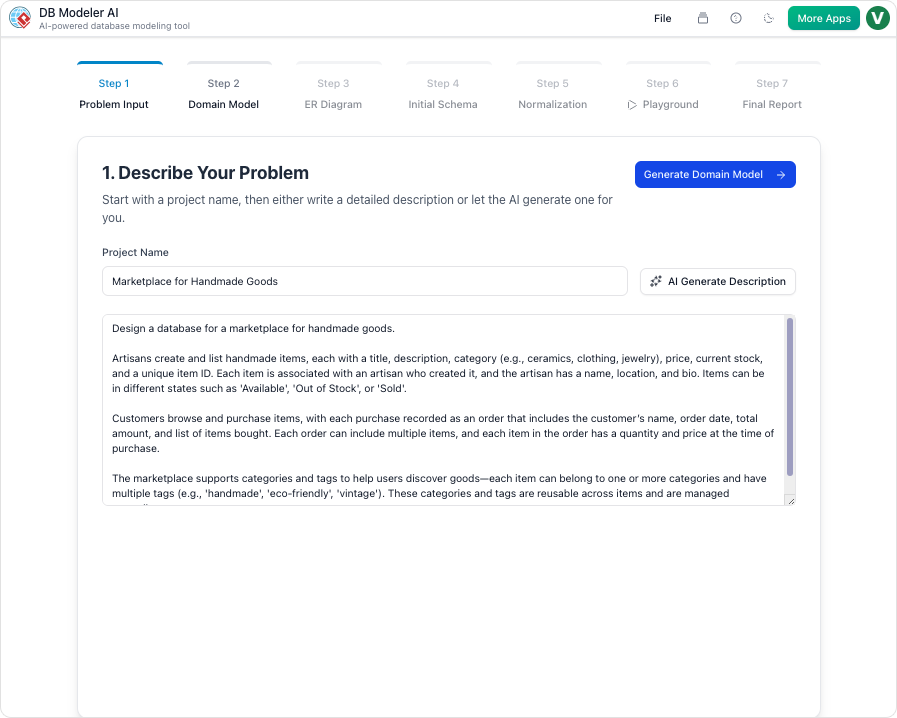
1. 問題の入力
このプロセスはシンプルなプロンプトから始まる。ユーザーはアプリケーションを平易な英語で説明する。たとえば:「オンライン書店用のデータベースを構築し、書籍、著者、顧客、注文を管理し、出荷状況の追跡を可能にする。」AIはこのテキストを分析し、核心的な要件を抽出する。
2. ドメインクラス図
テーブルやキーに飛び込む前に、AIはPlantUML構文を用いて高レベルの概念的ビューを生成する。これにより、対象となるオブジェクトとその関係性を抽象的に可視化でき、技術的実装の前に範囲が適切であることを確認できる。
3. ER図の生成
システムは概念モデルから詳細な論理モデルへ自動的に移行する。エンティティ関係図(ERD)テーブル、カラム、基数、主キー、外部キーを自動的に定義する。
4. 初期スキーマの生成
ER図がSQLデータ定義言語(DDL)に変換される。このツールは通常、PostgreSQLなど広く使われている標準をデフォルトとして採用し、現代のテクノロジースタックとの互換性を確保する。
5. インテリジェントな正規化
これは間違いなく最も重要なステップである。AIは段階的にスキーマを最適化し、データの整合性を確保する。
- 1NF(第一正規形): 原子性を確保します。複数値のフィールドを排除します(たとえば、セルに著者名のカンマ区切りリストが含まれないことを保証する)。
- 2NF(第二正規形): 部分的依存関係を除去します。非キー属性が主キー全体に依存することを保証し、多くの場合テーブルを分割します(たとえば、著者情報と本のテーブルを分離する)。
- 3NF(第三正規形): 推移的依存関係を排除します。カラムが主キーのみに依存し、他の非キー列に依存しないことを保証します。
重要なのは、AIが教育的な根拠をすべての決定に提供し、なぜテーブルが分割された理由を説明することで、強力な学習ツールとなります。
6. インタラクティブなプレイグラウンド
ローカルサーバーを必要とせず、ブラウザベースのSQL環境を提供します。AIが生成した現実的なサンプルデータでスキーマを自動的に埋めます。これにより、クエリやCRUD操作を即座にテストできます。
7. 最終レポートとエクスポート
検証が完了すると、ユーザーはMarkdown形式の設計レポートを生成し、SQLスクリプトをエクスポートし、PDFまたはJSON形式で図をダウンロードできます。これは開発チームの「唯一の真実の出所」として機能します。
実践例:オンライン書店の設計
このワークフローの力を示すために、元の資料で言及されたオンライン書店シナリオに適用してみましょう。
ステップ1:プロンプト
以下の要件を入力します:「オンライン書店のためのシステムが必要です。書籍(タイトル、著者、価格、カテゴリ、ISBN)と顧客(名前、メールアドレス、住所)、注文(日付、ステータス、合計)、注文項目を管理します。顧客は著者やカテゴリで検索し、注文を行い、出荷状況を追跡できます。」
ステップ2および3:構造の可視化
AIは即座にドメインクラス図を作成し、続いてER図を生成します。これにより、顧客は1:N との関係注文、そして書籍はN:M(多対多)の関係を持つ注文、これにより中間テーブルが必要となる注文項目 テーブル。
ステップ4および5:最適化と正規化
初期段階では、スキーマが著者の名前を書籍 テーブル内に直接格納する可能性がある。AIはこれを最適なデータベース設計に違反していると識別する。
- 行動: AIは
著者を独自のテーブルに抽出する。 - 結果:
書籍テーブルには著者IDの外部キーが含まれる。 - 利点: 冗長性が排除される。著者の名前が変更された場合、1か所でのみ更新すればよい。
ステップ6:プレイグラウンドでのテスト
スキーマが生成された後、AIは現実的なデータ(例:F・スコット・フィッツジェラルド著『グレート・ギャツビー』)でデータベースを初期化する。構造を検証するために、すぐにテストクエリを実行できる。
SELECT b.title, a.name
FROM books b
JOIN authors a ON b.author_id = a.id
WHERE b.category = '小説';クエリが期待される結果を返す場合、設計は即座に検証されます。
結論:アーキテクチャ的負債の削減
手作業による図面からAI駆動型アーキテクチャツールを介して、たとえばVisual Paradigm DB Modeler AI高品質なデータベース設計を民主化します。これにより、概念的なビジネス要件と技術的実装の間のギャップを埋めます。
かつては専門家の労力が何週間も必要で、高額な誤りのリスクを伴っていたことが、今では数分で完了できます。組み込みの教育機能、検証機能、共同作業機能を備え、この技術は学生、プロダクトマネージャー、開発者に、より迅速かつ信頼性の高いデータアーキテクチャの構築を可能にします。今後、データベースモデリングの基礎段階にAIを統合することは、アーキテクチャ的負債を削減し、イノベーションを加速するための標準となるでしょう。
