











1. 什么是数据库规范化?
数据库规范化是一种系统化方法用于在关系型数据库中组织数据,以实现:
- 最小化冗余(重复数据)
- 提高数据完整性(准确性和一致性)
- 防止异常(更新、插入和删除问题)
- 优化存储和查询性能
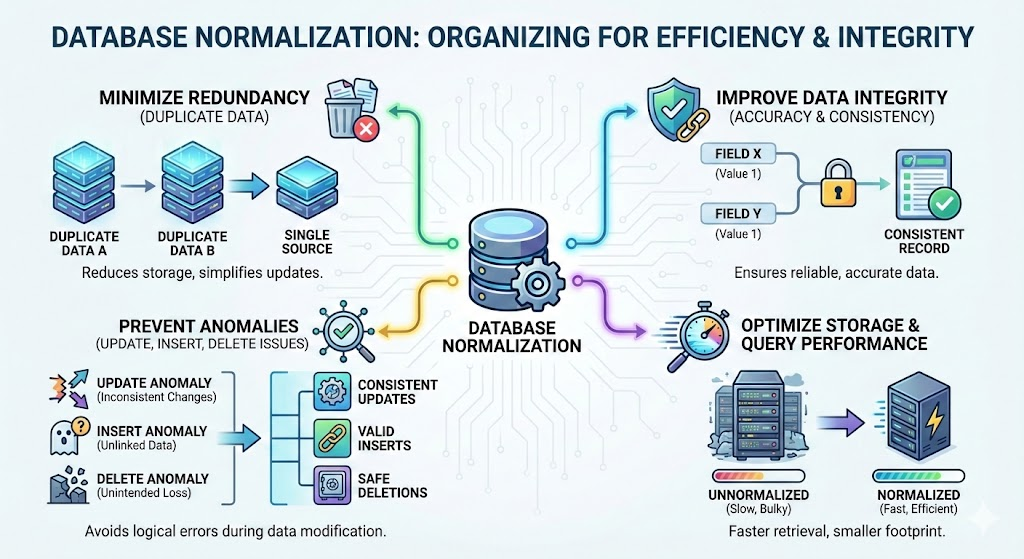
规范化通过以下方式实现这一点:分解表为更小且相关的表,并通过使用主键和外键.
2. 为什么要对数据库进行规范化?
规范化解决了数据库设计中的关键挑战:
| 问题 | 通过规范化解决 |
|---|---|
| 数据冗余 | 消除重复数据,降低存储成本和不一致性。 |
| 更新异常 | 确保数据更改(例如客户地址)仅在一个位置反映。 |
| 插入异常 | 在添加新数据时防止错误(例如,在没有客户的情况下插入新订单)。 |
| 删除异常 | 避免意外的数据丢失(例如,删除订单不应删除客户)。 |
| 查询效率 | 更小且结构良好的表格可以加快搜索速度并减少计算开销。 |
| 可扩展性 | 简化未来的修改(例如,添加新的字段或表格)。 |
3. 何时应该进行规范化?
规范化是至关重要的在以下场景中:
何时进行规范化
- 高数据冗余:如果您的数据库在多个位置存储相同的信息(例如,客户地址在多个表格中)。
- 频繁更新:如果数据经常变化(例如,库存系统、用户资料)。
- 复杂关系:如果实体之间存在多种关系(例如,学生、课程和教师)。
- 数据完整性至关重要:如果准确性不容妥协(例如,金融、医疗或法律系统)。
- 长期可扩展性:如果数据库预计会随时间增长或演变。
何时反规范化(或停在第三范式)
- 读取密集型应用:如果您的数据库被查询的频率远高于更新频率(例如,报告系统、分析仪表板)。
- 性能瓶颈:如果在规范化表格之间进行连接导致查询变慢(例如,高流量的电子商务网站)。
- 简单用例:如果数据库较小且不太可能增长(例如,个人联系人列表)。
4. 哪些人应该使用数据库规范化?
规范化适用于任何参与数据库设计、开发或管理的人:
| 角色 | 为何需要规范化 |
|---|---|
| 数据库管理员(DBAs) | 确保数据库结构高效、可靠且可扩展。 |
| 软件开发人员 | 设计易于维护、调试和扩展的数据库。 |
| 数据架构师 | 创建与业务需求一致的稳健数据模型。 |
| 学生/学习者 | 构建数据库设计和关系理论的基础知识。 |
| 产品经理 | 将业务需求转化为数据库模式的技术要求。 |
| 系统架构师 | 设计具有最优数据存储和检索机制的系统。 |
5. 如何规范化数据库:分步示例
规范化是通过一系列范式,每种范式解决特定类型的冗余和异常问题。以下是前三种范式(1NF、2NF、3NF)的实用指南,这些范式最常被使用。
第一范式(1NF)
规则:每个表单元格必须包含一个单一、原子值,且每一列必须有一个唯一名称。不允许重复组或数组。
示例:未规范化的表
| 订单ID | 客户 | 产品 |
|---|---|---|
| 1 | 约翰 | 苹果,香蕉 |
| 2 | 爱丽丝 | 葡萄,草莓 |
问题: 该产品列包含多个值。
解决方案:符合1NF的表
| 订单ID | 客户 | 产品 |
|---|---|---|
| 1 | 约翰 | 苹果 |
| 1 | 约翰 | 香蕉 |
| 2 | 爱丽丝 | 葡萄 |
| 2 | 爱丽丝 | 草莓 |
第二范式(2NF)
规则: 表必须处于1NF,并且所有非键属性必须依赖于整个主键(无部分依赖)。
示例:1NF 表(非 2NF)
| 学生ID | 课程ID | 课程名称 | 教师 |
|---|---|---|---|
| 1 | 101 | 数学 | 史密斯教授 |
| 1 | 102 | 物理 | 约翰逊教授 |
| 2 | 101 | 数学 | 史密斯教授 |
问题: 课程名称 和 教师 仅依赖于 课程ID,而非完整的主键(学生ID + 课程ID).
解决方案:符合 2NF 的表
学生表:
| 学号 | 学生姓名 |
|---|---|
| 1 | 约翰 |
| 2 | 爱丽丝 |
| 课程编号 | 课程名称 | 教师 |
|---|---|---|
| 101 | 数学 | 史密斯教授 |
| 102 | 物理 | 约翰逊教授 |
第三范式(3NF)
规则:表必须处于2NF,并且没有非主属性应依赖于另一个非主属性(无传递依赖)。
示例:2NF 表(非 3NF)
| 员工编号 | 项目编号 | 项目名称 | 负责人 |
|---|---|---|---|
| 1 | 101 | 项目A | 约翰 |
| 1 | 102 | 项目B | 爱丽丝 |
| 2 | 101 | 项目A | 约翰 |
问题: 经理 依赖于 项目ID,并非直接依赖于主键(员工ID + 项目ID).
解决方案:符合第三范式的表
员工表:
| 员工ID | 员工姓名 |
|---|---|
| 1 | 约翰 |
| 2 | 爱丽丝 |
项目表:
| 项目ID | 项目名称 |
|---|---|
| 101 | 项目A |
| 102 | 项目B |
员工项目表:
| 员工ID | 项目ID |
|---|---|
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
更高范式(BCNF、4NF、5NF)
- 博依斯-科德范式(BCNF):比3NF更严格;消除由函数依赖引起的全部冗余。
- 第四范式(4NF):处理多值依赖(例如,一本包含多位作者的书)。
- 第五范式(5NF):处理连接依赖(在实际中很少使用)。
6. 为什么可视化范式AI驱动的数据库规范化工具能够简化流程
手动规范化可能耗时、易出错且复杂,尤其是对于大型数据库。Visual Paradigm 的人工智能驱动的数据库规范化工具 自动化并简化了该过程,快速生成 可投入生产的数据库模式,仅需几分钟.
Visual Paradigm 人工智能工具的核心功能
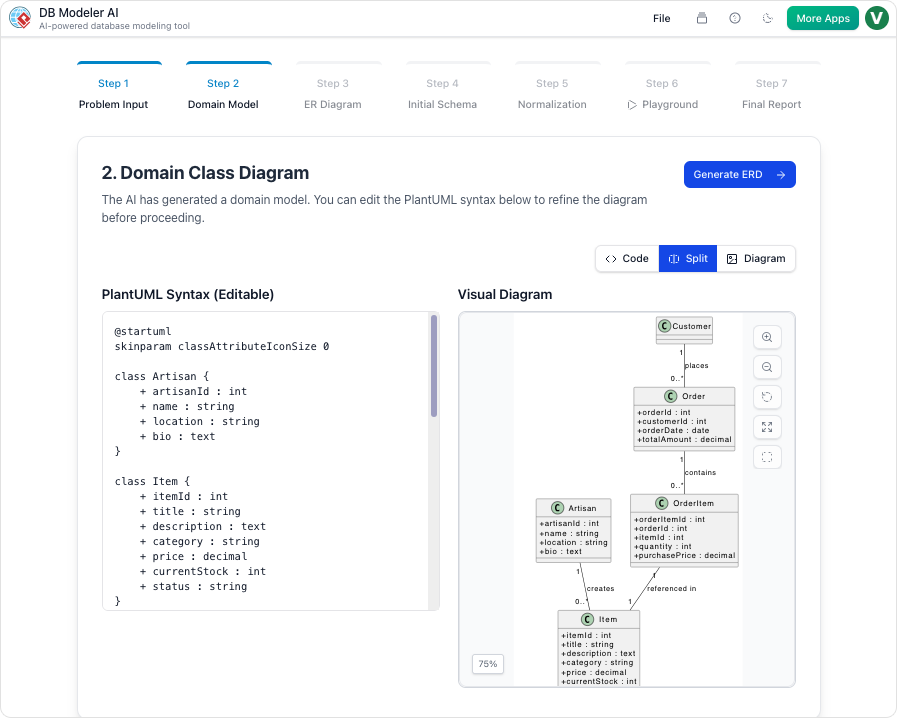
1. 自动生成可视化图表
- 它能做什么:生成清晰、专业的实体关系(ER)图 通过简单的英文描述生成。
- 为什么重要:可视化表之间的关系,使识别冗余和依赖关系变得更加容易。
- 示例:描述“一个包含书籍、作者和会员的图书馆系统”,工具将生成一个 完全规范化的模式 包含表、主键和关系。
2. 分步规范化指导
- 它能做什么:引导您完成从1NF 到 3NF(或更高)的规范化过程,附带每一步的详细说明.
- 为什么重要:帮助初学者学习规范化,同时确保专家不会出错。
- 示例:该工具会突出显示 2NF 中的部分依赖关系,并建议如何拆分表以达到 3NF。
3. 浏览器内实时 SQL 演练环境
- 它能做什么:让您运行真实的SQL查询 在你的规范化模式上 无需安装软件.
- 为什么这很重要: 立即测试你的设计,以确保其满足性能和完整性要求。
- 示例: 编写一个查询来连接表,并验证数据是否正确检索。
4. AI辅助工作流
- 它能做什么: 使用AI来 分析你的自然语言描述 并生成一个 完全规范化的数据库模式.
- 为什么这很重要: 节省数小时的手动工作,并减少人为错误。
- 示例: 输入: “一个包含医生、患者和预约信息的医院数据库。” 输出:一个 符合第三范式的模式 包含以下表格:
医生,患者,预约,以及它们之间的关系。
谁应该使用Visual Paradigm的AI工具?
| 角色 | 如何帮助 |
|---|---|
| 开发者 | 快速设计和验证任何规模项目的模式。 |
| 学生 | 通过互动式、实践性的工具学习规范化概念。 |
| 产品经理 | 在无需深入SQL知识的情况下,将业务需求转化为技术数据模型。 |
| 系统架构师 | 快速原型化复杂的数据关系并可视化系统设计。 |
7. 结论
数据库规范化是一种基础技能,用于设计高效、可扩展且无错误的数据库。通过遵循1NF、2NF 和 3NF规则,可以消除冗余,提高数据完整性,并优化性能。然而,手动规范化可能非常复杂且耗时.
Visual Paradigm 的人工智能驱动的数据库规范化工具通过以下方式简化该过程:
- 从自然语言描述中自动生成模式。
- 提供逐步指导用于规范化。
- 提供一个实时SQL沙盒用于测试设计。
- 生成可视化ER图以增强清晰度。
无论你是开发者、学生还是产品经理,这个工具能帮助你更快更智能地构建可投入生产的数据库.
准备试用了吗?
👉 立即使用 Visual Paradigm AI 开始设计你的数据库
你在项目中使用过数据库规范化吗?遇到了什么挑战? 来讨论一下吧!
