











引言
软件架构的格局正在经历一场地震般的变革。数十年来,任何稳健应用程序的基础——数据库——都是通过严格的手动劳动构建的。这一过程被称为数据库建模的演变,如今正从手工蓝图时代过渡到一个新时代人工智能驱动的架构.
传统上,设计数据结构需要深厚的专业知识、孤立的工具以及大量的时间投入。这是一个高摩擦过程,容易出现人为错误、冗余和架构债务。然而,诸如Visual Paradigm 的数据库建模人工智能等创新已经打破了这种现状。通过引入智能且有指导性的7步工作流程,这项技术利用生成式人工智能,将普通的英文描述转化为完全规范化的、可投入生产的数据库模式。
本全面指南探讨了这一演变过程,突出展示了传统方法与现代人工智能能力之间的显著差异。我们将通过一个经典的在线书店场景,展示人工智能如何消除传统痛点并加速专业数据库设计。
传统困境:手动限制与高摩擦
在人工智能出现之前,数据库建模被认为是一种需要大量人力的专门技艺,仅限于专业人士。这一过程充满挑战,常常拖慢开发周期并引入漏洞。
传统工作流程
- 空白画布:设计师会从 ER/Studio、Lucidchart 或甚至纸质笔和纸张中的空白工作区开始。没有任何起点优势;每个实体都必须从零开始构思。
- 手动识别:架构师必须手动识别实体, 属性, 关系, 主键(PK),以及外键(FK)这要求在绘制任何线条之前,就必须对业务逻辑有完美的心理模型。
- 规范化难题:从草图到部署模式的过程涉及规范化(1NF → 2NF → 3NF)。该过程旨在查找冗余、部分依赖和传递依赖。传统上,这需要繁琐的手动分析,极易出现疏漏和人为错误。
- 被动工具:旧工具仅充当数字绘图板。它们不提供智能建议,无法在概念模型与逻辑模型之间自动转换,也无法进行超出基本语法检查的验证。
- 测试孤岛:验证需要搭建本地数据库环境(例如,PostgreSQL、MySQL),手动编写
INSERT脚本,并希望查询能揭示完整性问题。
这种手动方法的结果通常是显著的架构债务、漫长的迭代周期,以及陡峭的学习曲线,使产品经理或学生等非专家无法参与设计过程。
人工智能驱动的范式转变
DB Modeler AI,可通过Visual Paradigm 的在线平台,代表了我们处理数据方式的根本性变革。它不仅是一个工具,更是一个“智能副驾驶”。通过利用自然语言处理(NLP)和丰富的领域知识,它能够理解业务需求,并生成符合标准的模型。
对比:传统方法与人工智能驱动建模
下表概述了传统手动方法与现代人工智能驱动工作流程之间的关键操作差异。
| 功能 | 传统手动方法 | 人工智能驱动方法(DB Modeler AI) |
|---|---|---|
| 输入机制 | 手动拖放;显式定义每一列。 | 自然语言(纯英文描述)。 |
| 速度 | 复杂模式需要数天或数周。 | 从概念到规范化模式只需几分钟。 |
| 规范化 | 手动分析;容易出现人为错误和疏漏。 | 自动化、分步指导(1NF、2NF、3NF),附带详细解释。 |
| 验证 | 需要外部数据库设置和手动编写脚本。 | 即时的浏览器内SQL沙盒,配备AI生成的测试数据。 |
| 可访问性 | 需要深厚的SQL/架构知识。 | 对开发人员、产品经理、学生和架构师均易于使用。 |
| 输出质量 | 完全依赖于用户的技能水平。 | 标准化、符合最佳实践、可直接用于生产的DDL。 |
七步引导式工作流程
Visual Paradigm其数据库建模AI采用透明的七步流程,引导用户从模糊的想法逐步构建出具体且经过验证的数据库模式。
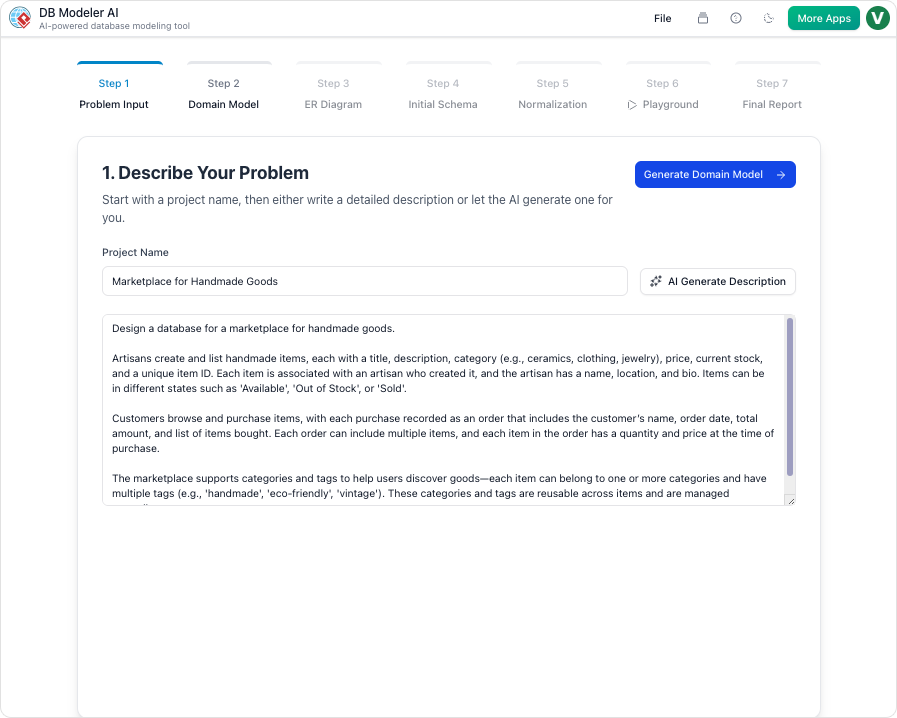
1. 问题输入
该流程从一个简单的提示开始。用户用通俗易懂的英语描述其应用程序。例如:“构建一个在线书店的数据库,用于管理书籍、作者、客户、订单,并支持订单物流追踪。”AI将分析此文本以提取核心需求。
2. 领域类图
在深入表格和键之前,AI会使用PlantUML语法生成高层次的概念视图。这有助于以抽象方式可视化对象及其关系,确保在技术实现前范围准确无误。
3. ER图生成
系统会自动从概念模型过渡到详细的逻辑实体-关系图(ERD)。它会自动定义表、列、基数、主键和外键。
4. 初始模式生成
ER图被转换为SQL数据定义语言(DDL)。该工具通常默认采用广泛使用的标准,如PostgreSQL,以确保与现代技术栈的兼容性。
5. 智能规范化
这无疑是最重要的一步。AI逐步优化模式以确保数据完整性:
- 1NF(第一范式): 确保原子性。它消除了多值字段(例如,确保单元格不包含用逗号分隔的作者列表)。
- 2NF(第二范式): 消除部分依赖。它确保非键属性依赖于整个主键,通常通过拆分表实现(例如,将作者信息从书籍表中分离)。
- 3NF(第三范式): 消除传递依赖。它确保列仅依赖于主键,而不依赖于其他非键列。
至关重要的是,AI提供了教育性理由用于每个决策,解释为什么表被拆分的原因,使其成为一个强大的学习工具。
6. 交互式沙盒
无需本地服务器,该工具提供基于浏览器的SQL环境。它会自动使用真实且由AI生成的示例数据填充模式。这使得可以立即测试查询和CRUD操作。
7. 最终报告与导出
验证后,用户可以生成Markdown格式的设计报告,导出SQL脚本,并以PDF或JSON格式下载图表。这为开发团队提供了一个“唯一可信来源”。
实际案例:设计一个在线书店
为了展示这一工作流程的强大功能,让我们将其应用于在线书店源材料中提到的情景。
步骤1:提示
我们输入以下需求:“我需要一个在线书店的系统,用于管理书籍(包括标题、作者、价格、类别、ISBN)、客户(姓名、邮箱、地址)、订单(日期、状态、总额)以及订单项。客户可以按作者或类别浏览,下单并跟踪发货情况。”
步骤2与3:可视化结构
AI立即创建一个领域类图,接着是一个实体关系图。它识别出一个客户拥有一个1:N 与 …… 的关系订单,并且书籍 与 N:M(多对多)关系与订单,需要一个中间表订单项 表。
步骤 4 和 5:优化与规范化
最初,该模式可能将作者姓名直接存储在书籍 表中。AI 将此识别为违反最优数据库设计。
- 操作: AI 将
作者提取到其独立的表中。 - 结果:
书籍表现在包含一个作者ID外键。 - 优势: 这消除了冗余;如果作者更改姓名,只需在一个地方更新即可。
步骤 6:在沙盒中测试
在生成模式后,AI 使用真实数据填充数据库(例如,F·斯科特·菲茨杰拉德著的《了不起的盖茨比》)。我们可以立即运行测试查询以验证结构:
SELECT b.title, a.name
FROM books b
JOIN authors a ON b.author_id = a.id
WHERE b.category = '小说';如果查询返回预期结果,设计将立即得到验证。
结论:减少架构债务
从手工蓝图到人工智能驱动的架构通过类似Visual Paradigm 数据库模型设计器 AI使高质量的数据库设计普及化。它弥合了概念性业务需求与技术实现之间的差距。
过去需要数周专家劳动且存在高昂错误风险的工作,现在只需几分钟即可完成。借助内置的教育、验证和协作功能,这项技术使学生、产品经理和开发人员能够更快、更可靠地构建数据架构。随着我们不断前进,将人工智能整合到数据库建模的基础阶段,很可能成为减少架构债务和加速创新的标准。
