











如何为敏捷开发估算用户故事
估算用户故事很难!我们如何才能获得最准确的故事规模估算?有些人认为最佳的估算方式应以故事点来衡量,而另一些人则更倾向于以小时或天数来估算。
确实,估算很困难,但有一些概念可以帮助我们在用户故事估算过程中取得进展:
- 从两个方面以相对的方式估算用户故事:
- 工作量
- 风险(例如,复杂性和不确定性)
- 使用故事点来估算用户故事
- 将那些你在工作量和复杂性(风险)方面更有把握估算的用户故事放入亲和力表中
- 通过将其他不太熟悉的用户故事与亲和力表中已估算过的那些故事进行比较,逐步估算它们的工作量和复杂性。
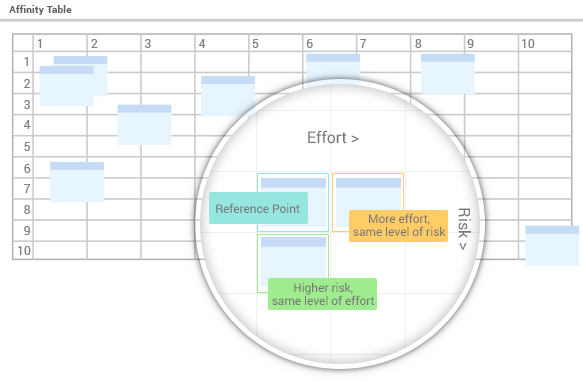
用于估算的用户故事亲和力
用户故事的估算永远无法达到100%的准确,事实上没有任何方法可以做到这一点。为了提高估算的准确性,我们首先确定冲刺周期长度(例如,两周或10个工作日),并对少数我们最熟悉的用户故事进行估算(例如,5天,确定性为中等)。在这种情况下,你将在垂直方向上将该故事放在中间位置(确定性或风险水平),水平方向上将其放在5天的位置(即冲刺周期长度10天的一半)。然后你可以将其作为其他用户故事估算的参考点。问自己:这个用户故事所需的工作量是否比参考项更多或更少,风险是否更高或更低。当你在亲和力表上放置更多用户故事后,可以比较多个故事,判断其相对位置是否合理,然后进行调整,使其更加公平。这个过程更像是一种艺术而非工程。应在团队会议中讨论和实施,而不是引发冲突。随着团队逐渐成熟,估算的准确性通常会提高。用户故事我们最熟悉其估算的用户故事(例如,5天,确定性为中等)。在这种情况下,你将在垂直方向上将该故事放在中间位置(确定性或风险水平位置)和水平方向(工作工作量工作量等于5天,或冲刺周期长度10天的一半)。然后你可以将其作为其他用户故事估算的参考点。问自己:这个用户故事所需的工作量是否比参考项更多或更少,风险是否更高或更低。当你在亲和力表上放置更多用户故事后,可以比较多个故事,判断其相对位置是否合理,然后进行调整,使其更加公平。这个过程更像是一种艺术而非工程。应在团队会议中讨论和实施,而不是引发冲突。随着团队逐渐成熟,估算的准确性通常会提高。
亲和力表是如何计算的?(观看视频)
为了理解亲和力表中故事点和天数是如何自动估算的,我们需要明白:水平网格代表工作量,从左到右递增;而故事开发的复杂性(例如新技术、新领域等)则从上到下递增。
由于用户故事开发的最大天数不应超过冲刺周期的长度(否则,要么用户故事过大需要拆分,要么冲刺周期设置过短需要延长),因此右下角网格的天数也应等于冲刺周期的长度。基于这一假设,故事估算可以自动计算。

请注意:在上例中
故事点 = 工作量 × 风险(例如:3 × 4 = 12)
故事点单位 = 总点数 / 冲刺周期长度(例如:100 / 20)= 0.2
故事天数(小时)= 故事点 / 故事点单位(例如:12 × 0.2)= 2.4
通过项目探针消除风险
根据敏捷词典,Spike的定义是:
“一项旨在回答问题或收集信息的任务,而不是为了生产可交付的产品。有时会生成一个用户故事,直到开发团队实际完成一些工作以解决技术问题或设计问题之前,无法准确估算。解决方案是创建一个“Spike”,即一项旨在提供答案或解决方案的工作。”
在估算用户故事时,我们不仅考虑开发工作量,还要考虑涉及的风险和不确定性。通常在冲刺正式开始之前会创建一个Spike,以管理为公平估算其他用户故事所需完成的工作。
