











通过系统化的文本分析,将自然语言需求转化为专业的UML类图——一种结构化、教育性和实用性的入门方法。
✅ 为什么要使用文本分析来绘制类图?
文本分析是一种基础性技术,应用于面向对象分析与设计(OOAD)。它弥合了非正式问题描述(用户故事、需求或系统规范)与正式UML类图.
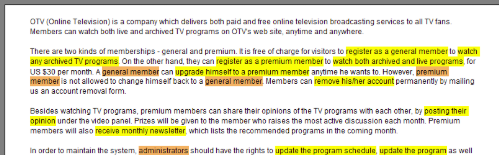
对于初学者而言,这种方法提供了一种清晰且可重复的过程以无需猜测的方式提取系统的核心结构。
🎯 文本分析的关键优势
| 优势 | 说明 |
|---|---|
| 结构化起点 | 不再有面对空白页面的焦虑——类可以直接从文本中浮现。 |
| 提升完整性 | 捕捉到在头脑风暴中可能被遗漏的领域实体。 |
| 更高的准确性 | 减少无关类的虚构或关键概念的遗漏。 |
| 教授核心UML概念 | 名词 → 类,动词 → 操作,介词 → 关系。 |
| 增强沟通 | 可视化图表有助于利益相关者、开发人员和团队成员达成一致。 |
| 加速建模 | 手动分析有助于建立理解;自动化则加快迭代速度。 |
| 支持迭代优化 | 鼓励审查、验证和持续改进。 |
这种方法根植于经典OOAD原则,源自如《UML与模式应用》 作者:克雷格·拉尔曼。
🔑 文本分析中的关键概念
在深入过程之前,先理解这些核心的UML建模元素:
1. 候选类
-
名词或名词短语 代表领域中持久且有意义的实体。
-
关注领域对象,而非实现细节。
-
示例:
成员,书籍,借阅,订单,账户.
❌ 排除:临时项目(例如“借阅会话”)、同义词(例如“用户”与“成员”),或技术产物(例如“数据库”)。
2. 属性
-
类的特征或属性。
-
通常源自与类相关的名词.
-
示例:
书籍具有属性:标题,作者,ISBN,状态.
3. 操作(方法)
-
类可以执行的操作或对其执行的操作。
-
源自动词或动词短语在文本中。
-
示例:
成员.borrowBook(),图书管理员.addBook().
4. 关系
类之间如何交互。使用UML的标准关系类型:
| 关系 | 含义 | 示例 |
|---|---|---|
| 关联 | 类之间的通用连接 | 成员 与……关联 贷款 |
| 聚合 | “拥有”(部分-整体,弱拥有关系) | 图书馆 聚合 书 |
| 组合 | 强“拥有”(整体拥有部分) | 订单 组合 订单项 |
| 继承(泛化) | “是-一种”关系 | 储蓄账户 是-一种 账户 |
⚠️ 多重性(例如,
1,0..1,1..*,0..*表示涉及多少个实例。
5. 其他UML元素
-
可见性:
+(公开),-(私有),#(受保护) -
数据类型:
字符串,整数,日期,布尔值 -
约束:
{有序},{唯一},等等
🛠 分步手动流程示例
让我们通过一个实际例子来逐步讲解,使用一个 图书馆管理系统.
📝 问题陈述
“图书馆管理系统允许会员借阅和归还书籍。每位会员都有唯一的ID和姓名。书籍包含书名、作者、ISBN以及状态(可借或已借出)。图书管理员可以添加新书、搜索书籍并管理借阅。当会员借书时,系统会记录借阅日期和到期日期。如果逾期,将计算罚款。”
步骤1:阅读并标记文本
下划线 名词/名词短语和圈出动词/动作.
“一个图书馆管理系统允许会员去借和归还 书籍每个会员有一个唯一标识和姓名. 书籍有标题, 作者, ISBN,以及状态(可借或已借出)。图书管理员可以添加新的书籍, 搜索查找书籍,并且管理 借阅。当一名成员 借阅一本书时,系统会记录借阅日期和到期日期。如果逾期, 罚款被计算.”
步骤2:识别候选类
| 名词/短语 | 原因 | 类? |
|---|---|---|
| 图书馆管理系统 | 系统名称(不是类) | ❌ |
| 成员 | 持久化实体 | ✅ 成员 |
| 书籍 | 核心领域对象 | ✅ 书籍 |
| 图书管理员 | 具有职责的角色 | ✅ 图书管理员 |
| 借阅 | 事务性概念 | ✅ 借阅 |
| 罚款 | 财务后果 | ✅ 罚款 |
| ID、姓名、标题、作者、ISBN、状态、借阅日期、到期日期 | 属性 | — |
| 借出、归还、添加、搜索、管理、计算 | 操作 | — |
✅ 最终候选类:
-
成员 -
书籍 -
图书管理员 -
借阅 -
罚款
📌 注意:
罚款可以建模为值对象或类具体取决于复杂性。我们将它包含在内以确保完整性。
步骤 3:识别属性
| 类 | 属性 | 文本来源 |
|---|---|---|
成员 |
ID, 姓名 |
“唯一ID和姓名” |
书籍 |
标题, 作者, ISBN, 状态 |
“书名、作者、ISBN、状态” |
借阅 |
借出日期, 应还日期 |
“记录借出日期和应还日期” |
罚款 |
金额, 是否逾期 |
“如果逾期,将计算罚款” |
💡 提示:避免冗余。不要重复属性,例如
状态在两者中图书和借阅.
步骤 4:识别操作(方法)
| 类 | 操作 | 文本来源 |
|---|---|---|
成员 |
borrowBook(), returnBook() |
“借书和还书” |
图书 |
updateStatus() |
由状态变更隐含 |
图书管理员 |
addBook(), searchBook(), manageLoan() |
“添加新书,搜索书籍,管理借阅” |
借阅 |
calculateFine() |
“罚款已计算” |
罚款 |
calculateAmount() |
由“罚款已计算”隐含 |
🔄 注意:某些操作可能更适合放在
图书管理员或借阅取决于职责。
步骤5:识别关系
| 关系 | 方向 | 多重性 | 原因 |
|---|---|---|---|
成员 — 借阅 |
成员 → 借阅 |
1..* |
一个成员可以有多个借阅 |
书 — 借阅 |
书 → 借阅 |
1..1 |
每本书(每一份副本)只能有一个借阅 |
图书管理员 — 书 |
图书管理员 → 书 |
1..* |
图书管理员添加/管理多本书 |
图书管理员 — 借阅 |
图书管理员 → 借阅 |
1..* |
图书管理员管理多个借阅 |
借阅 — 罚款 |
借阅 → 罚款 |
0..1 |
只有逾期贷款会产生罚款 |
⚠️ 多重性说明:
-
1..*= 一对多 -
0..1= 可选(零个或一个) -
1..1= 恰好一个
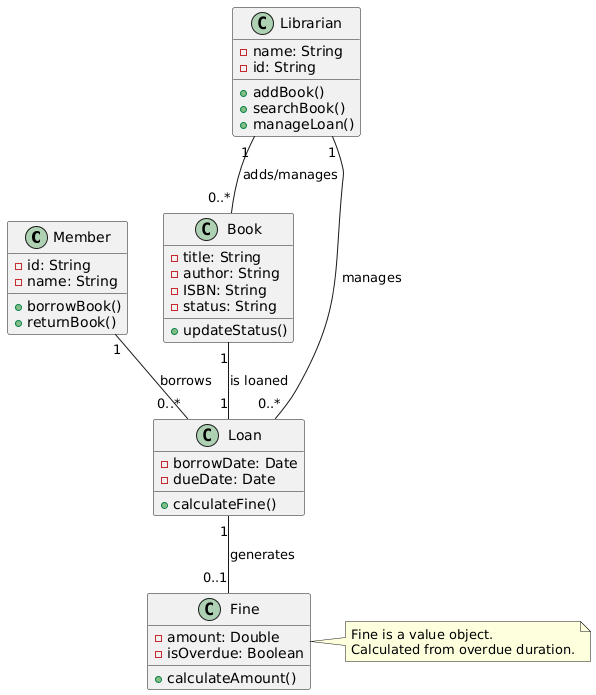
步骤 6:绘制类图
以下是PlantUML 用于最终类图的代码:
@startuml
' 定义类
class Member {
- id: 字符串
- name: 字符串
+ borrowBook()
+ returnBook()
}
class Book {
- title: 字符串
- author: 字符串
- ISBN: 字符串
- status: 字符串
+ updateStatus()
}
class Loan {
- borrowDate: 日期
- dueDate: 日期
+ calculateFine()
}
class Librarian {
- name: 字符串
- id: 字符串
+ addBook()
+ searchBook()
+ manageLoan()
}
class Fine {
- amount: 双精度
- isOverdue: 布尔值
+ calculateAmount()
}
' 定义关系
Member "1" -- "0..*" Loan : 借出
Book "1" -- "1" Loan : 已借出
Librarian "1" -- "0..*" Book : 添加/管理
Librarian "1" -- "0..*" Loan : 管理
Loan "1" -- "0..1" Fine : 产生
' 可选:如果 Fine 是值对象,添加构造型
note right of Fine
Fine 是一个值对象。
根据逾期时长计算。
end note
' 样式
skinparam shadowing false
skinparam rectangle {
BackgroundColor 白色
BorderColor 黑色
FontSize 12
}
@enduml
🖼️ 可视化输出(由 PlantUML 渲染)
📌 如何查看:将代码粘贴到PlantUML Live 或使用任何兼容 PlantUML 的编辑器(例如,带有插件的 VS Code、IntelliJ、Visual Paradigm)。
📊 图表概览:
-
类 以三个部分(名称、属性、操作)的矩形显示。
-
关联 是带有多重性标签的线条。
-
关系反映领域逻辑和职责。
-
注意在
很好明确了其作为值对象的角色。
🤖 通过可视化原型的AI驱动文本分析实现自动化
为了更快地建模和学习,可视化原型(VP)提供一个AI驱动的文本分析工具可自动化整个流程。
✅ 为什么要使用AI工具?
| 优势 | 描述 |
|---|---|
| 即时类检测 | AI扫描文本并建议类、属性和操作。 |
| 自动关系检测 | 识别关联、组合和多重性。 |
| 透明度 | 显示包含或排除的原因(例如,“‘library’是一个系统,而不是一个类”)。 |
| 减少错误 | 最大限度减少人为疏忽和不一致。 |
| 通过示例学习 | 将AI输出与您的手动分析进行对比。 |
🧩 它是如何工作的(逐步说明)
-
启动可视化原型
-
打开桌面版或在线版。
-
转到工具 > 应用程序 > 文本分析.
-
-
输入或生成问题描述
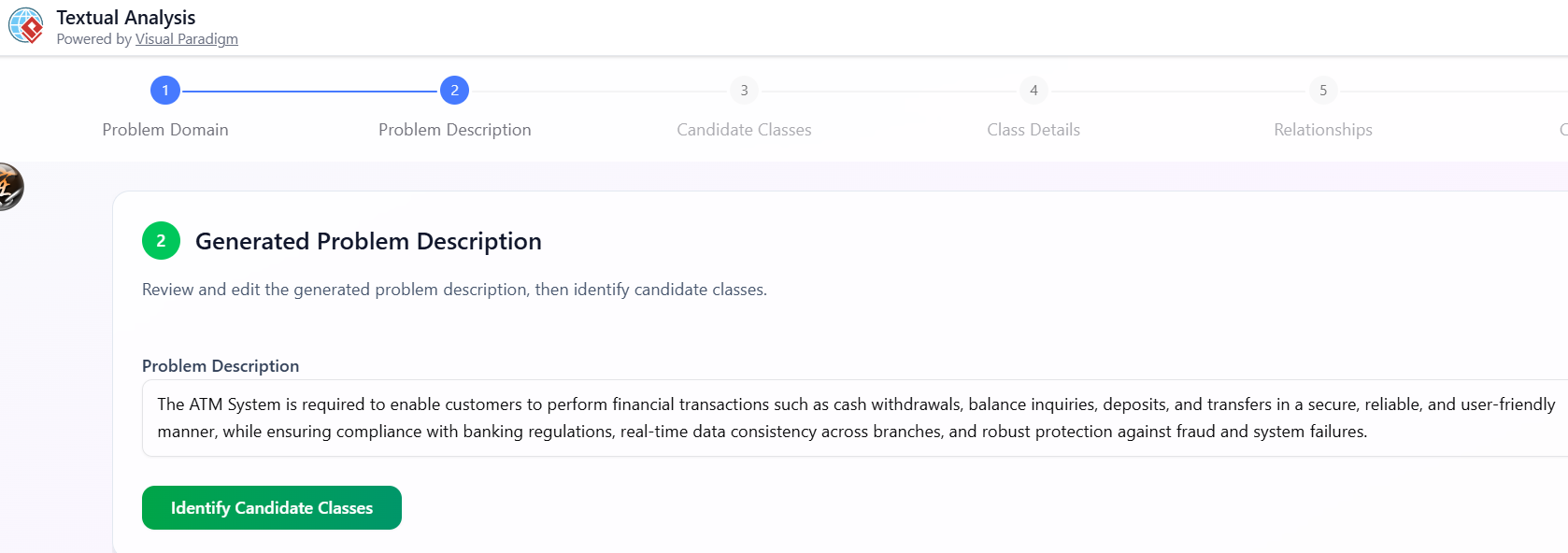
-
类型:
“图书馆管理系统” -
点击生成问题描述→ AI生成一段详细的文字。
-
编辑以符合您的具体需求(或粘贴您自己的内容)。
-
-
识别候选类
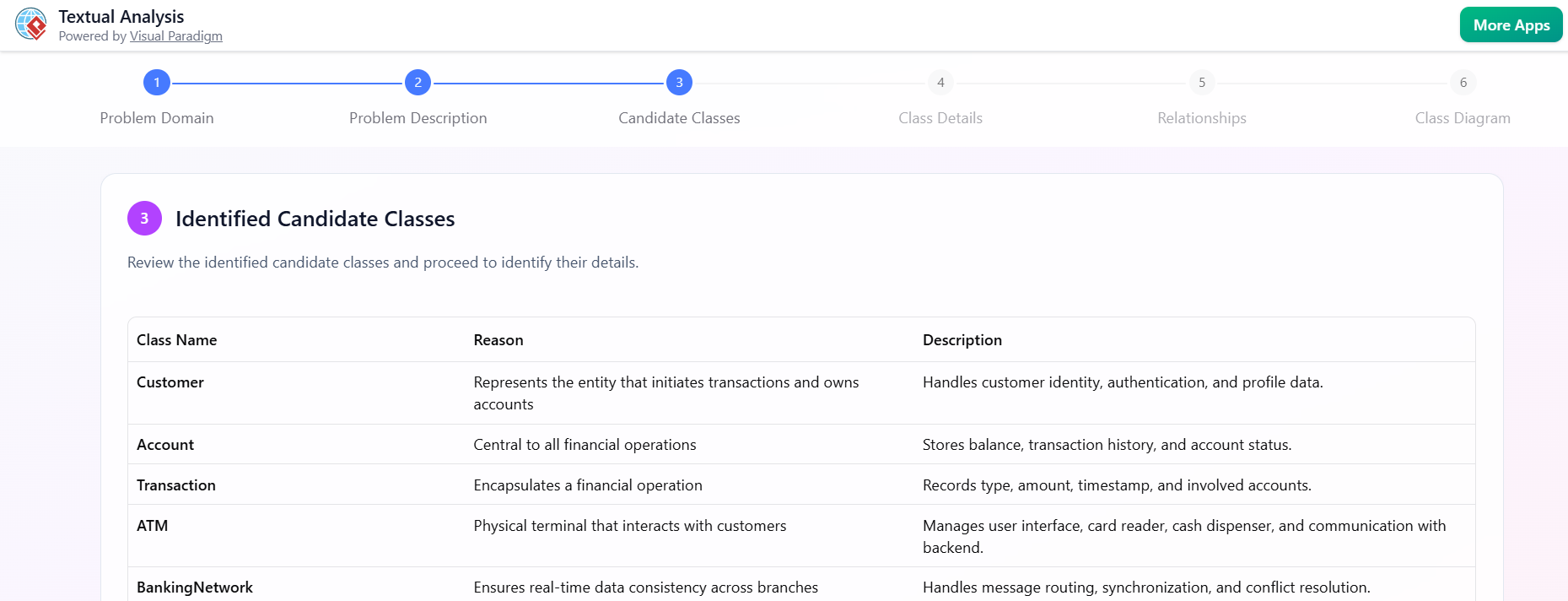
-
点击识别候选类.
-
AI返回一个表格:
类名 | 原因 | 描述 ---------------|---------------------------|------------------------- 成员 | 名词:持久实体 | 借书的人 书籍 | 名词:核心对象 | 带有ISBN的实体书籍 借阅 | 名词:事务性概念 | 借书记录 图书管理员 | 名词:角色 | 管理系统的工作人员 罚款 | 名词:结果 | 逾期未还的经济处罚 -
切换查看被排除的名词和原因(例如,“‘图书馆’是一个系统,而不是一个类”)。
-
-
识别类的详细信息
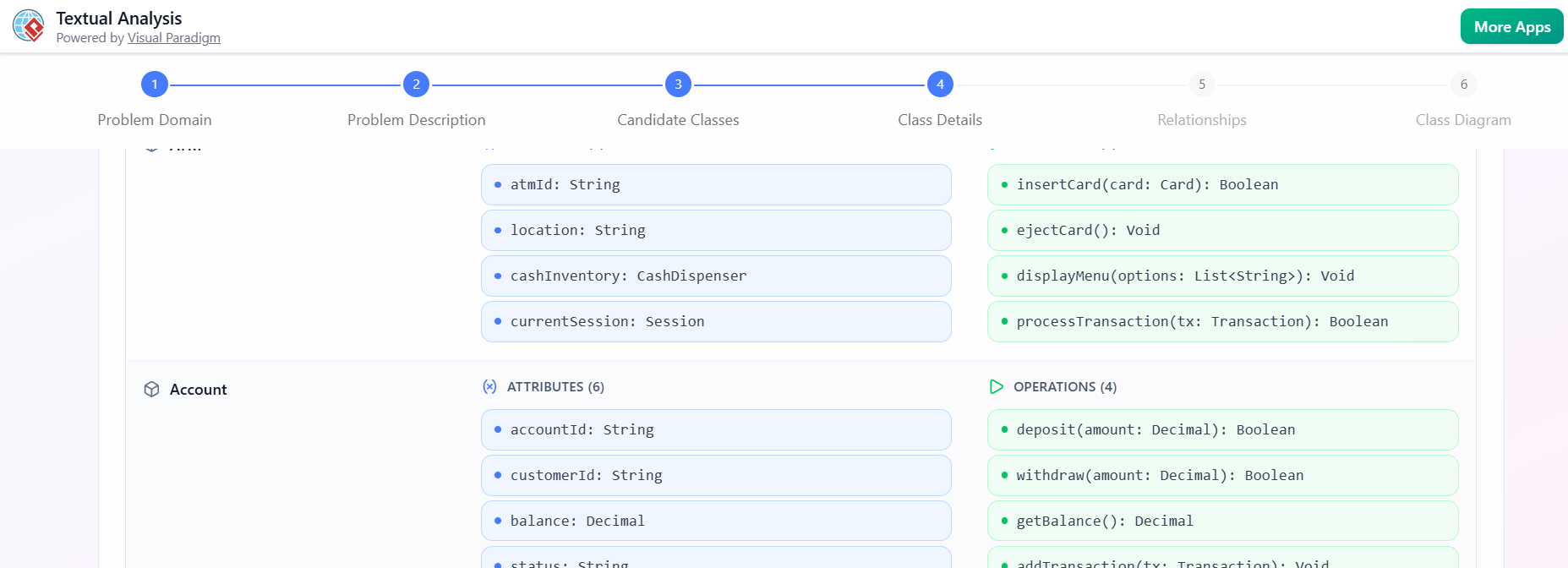
-
点击识别类的详细信息.
-
AI建议:
-
成员:编号,姓名 -
书籍:标题,作者,ISBN,状态 -
借阅:借出日期,应还日期 -
罚款:金额,是否逾期
-
-
-
识别类关系
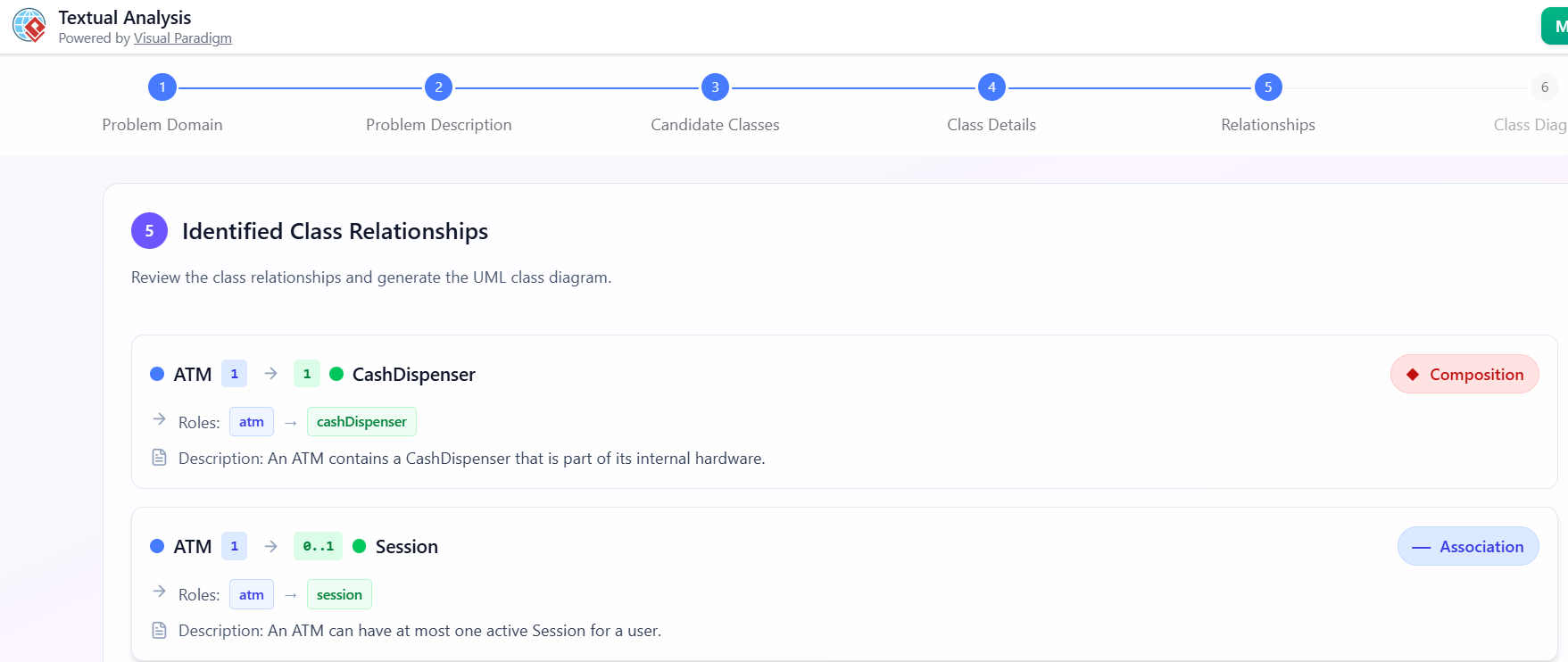
点击识别类关系.
-
AI建议:
-
会员—借阅(1..*) -
书籍—借阅(1..1) -
图书管理员—书(1..*) -
图书管理员—借阅(1..*) -
借阅—罚款(0..1)
-
-
-
生成图表
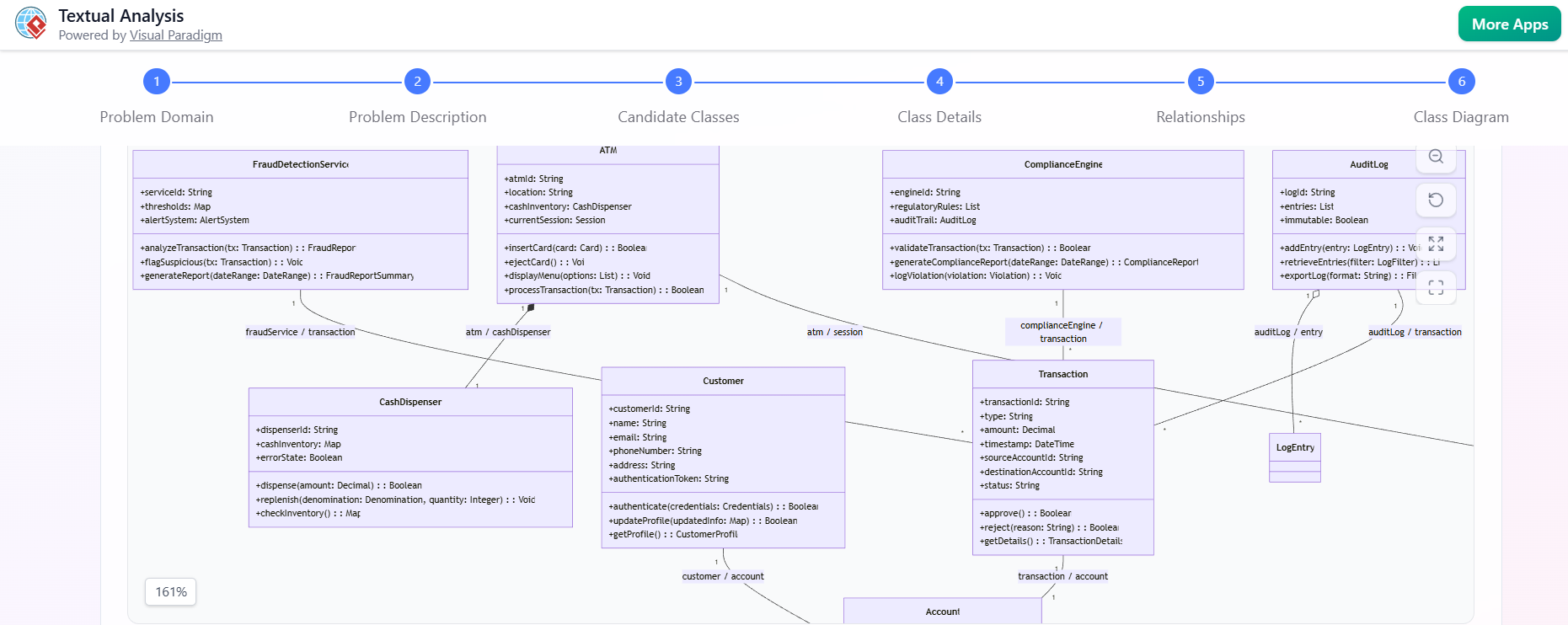
点击生成图表.
-
一个完全渲染且可编辑的UML 类图会立即出现。
-
✅ 专业提示:将 AI 输出作为初稿。然后手动优化:
调整多重性
添加可见性(
+,-)重新组织布局
应用命名规范
🎓 初学者的最佳实践
| 练习 | 为什么重要 |
|---|---|
| 开始手动操作 | 深入理解 UML 和领域建模。 |
| 对比 AI 与手动操作 | 了解 AI 为何做出某些选择;发现错误。 |
| 迭代并优化 | 模型随着反馈不断演变——不要一开始就追求完美。 |
| 使用简单示例 | 从以下示例开始:“在线购物车”、“ATM 系统”、“学生注册”。 |
| 避免过度设计 | 不要添加所有可能的属性或操作——专注于核心领域。 |
| 与利益相关者验证 | 确保模型反映现实需求。 |
🧩 实践中的真实用例
尝试以下适合初学者的系统来检验你的技能:
| 系统 | 关键类 | 学习重点 |
|---|---|---|
| 在线购物车 | 客户, 产品, 购物车, 订单, 付款 |
聚合,组合 |
| ATM系统 | 用户, 账户, 卡, 交易, 取款 |
继承,操作 |
| 学生注册 | 学生, 课程, 注册, 讲师 |
多对多关系 |
| 任务管理应用 | 用户, 任务, 项目, 截止日期 |
关联关系,多重性 |
🧠 最终思考与建议
文本分析是行业标准将需求转化为设计的黄金标准。它教你像设计师一样思考——而不仅仅是编写代码。
🎯 推荐工作流程:
-
首先进行手动分析 → 建立理解。
-
使用AI工具(例如:Visual Paradigm) → 加速建模并验证。
-
手动优化 → 提升清晰度、准确性和设计质量。
-
迭代 → 利用反馈来优化模型。
🌟 核心要点:
首先学习手动流程。将AI作为强大的助手——而非替代品。
-
AI文本分析——自动将文本转换为可视化模型:此功能利用AI分析文本文档,并自动生成如UML、BPMN和ERD等图表,以加快建模和文档编写。
-
从问题描述到类图:AI驱动的文本分析:本指南探讨了Visual Paradigm如何利用AI将自然语言的问题描述转化为准确的类图,用于软件建模。
-
由Visual Paradigm提供的AI驱动UML类图生成器:此先进的AI辅助工具可从自然语言描述中自动生成UML类图,简化软件设计流程。
-
使用Visual Paradigm进行软件设计的AI驱动文本分析教程: 本全面教程展示了如何利用人工智能驱动的文本分析,直接从……中提取关键的软件设计元素自然语言需求.
-
案例研究:利用人工智能驱动的文本分析生成UML类图: 一个深入的案例研究,展示了如何通过人工智能驱动的文本分析,从……准确生成UML类图非结构化需求.
-
在Visual Paradigm中利用人工智能文本分析识别领域类: 本资源教授用户如何自动检测……领域类通过专用的人工智能驱动分析工具,从文本输入中提取。
-
人工智能如何提升Visual Paradigm中的类图创建: 本文探讨了该平台如何利用人工智能自动化创建类图,使软件设计更加迅速且准确。
-
真实案例研究:使用Visual Paradigm AI生成UML类图: 一个实际案例研究,展示了人工智能助手如何成功地将……转换为准确的UML类图文本需求在一个实际项目中生成准确的UML类图。
-
使用人工智能和Visual Paradigm创建图书馆系统的UML类图: 一篇实践性博客文章,详细介绍了为……构建类图的过程图书馆管理系统使用人工智能。
-
Visual Paradigm AI工具箱:用于软件建模的文本分析工具: 该工具专注于将……转换为结构化的软件模型非结构化文本通过识别实体、关系和关键架构概念,将非结构化文本转化为结构化的软件模型。
