











Die Gestaltung zuverlässiger Steuerungssysteme für die Robotik erfordert Präzision. Ein einziger Logikfehler in der Firmware kann die Operationen stoppen oder Hardwarebeschädigungen verursachen. Zustandsmaschinen bieten einen strukturierten Ansatz zur Verwaltung komplexer Verhaltensweisen. Wenn sie korrekt implementiert werden, erhöhen sie Vorhersehbarkeit und Wartbarkeit. Eine falsche Gestaltung birgt jedoch Risiken wie Deadlocks. Diese Zustände blockieren das System und verhindern weitere Fortschritte.
Diese Anleitung untersucht Best Practices für UML-Zustandsmaschinen-Diagramme. Der Fokus liegt auf Kontexten der Robotik-Firmware. Wir untersuchen, wie Übergänge strukturiert, Ressourcen verwaltet und Konkurrenz behandelt werden können. Ziel ist Robustheit ohne unnötige Komplexität.
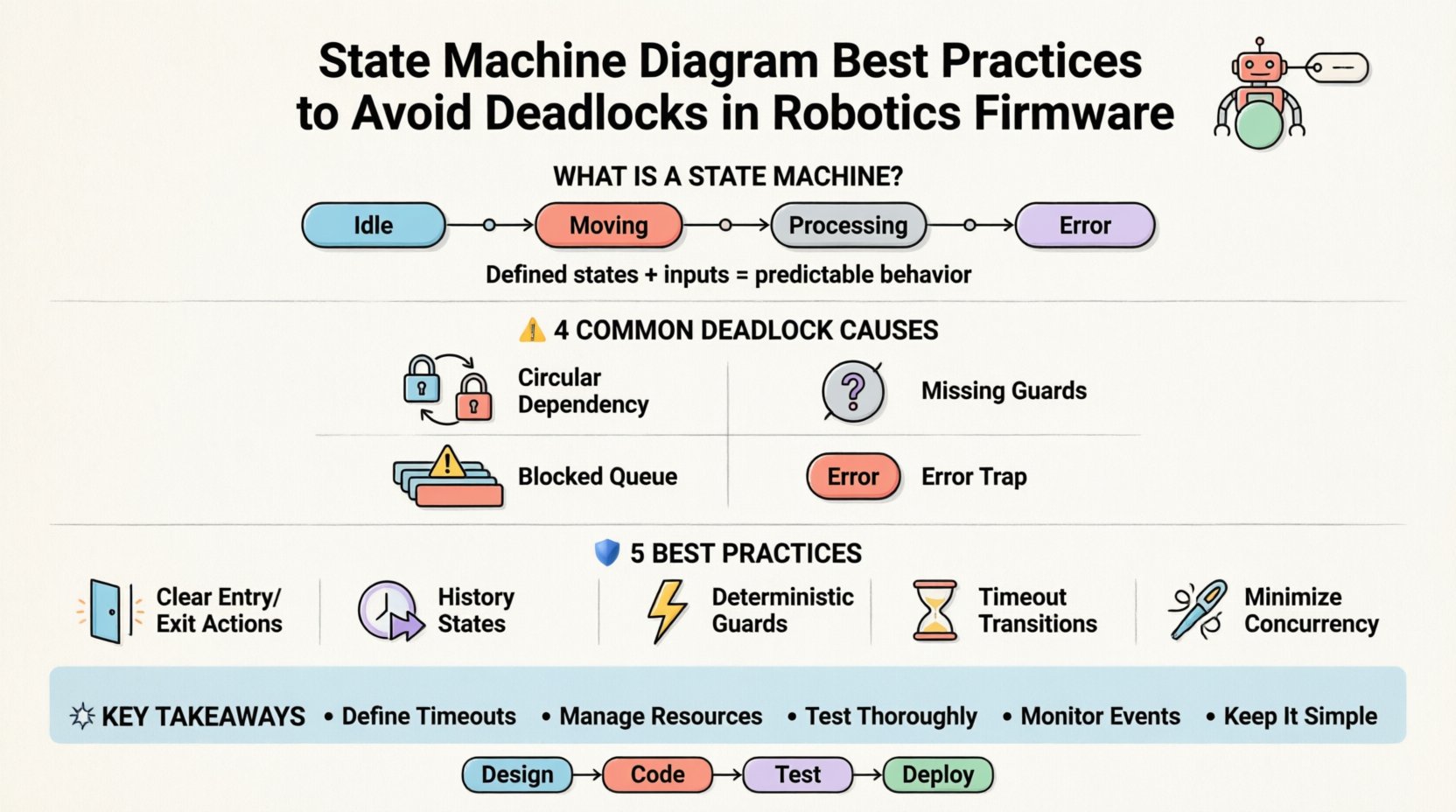
🧠 Verständnis von Zustandsmaschinen in der Robotik
Eine Zustandsmaschine ist ein mathematisches Modell der Berechnung. Sie beschreibt ein System, das zwischen definierten Zuständen aufgrund von Eingaben wechselt. In der Robotik stammen diese Eingaben oft von Sensoren, Benutzerbefehlen oder internen Zeitgebern. Die Zustände repräsentieren spezifische Betriebsmodi, wie beispielsweise „Wartend“, „Bewegung“, „Verarbeitung“ oder „Fehler“.
Warum Zustandsmaschinen verwenden?
- Klarheit:Visuelle Diagramme zeigen den Logikfluss klar.
- Vollständigkeit:Stellt sicher, dass alle Szenarien berücksichtigt werden.
- Wartbarkeit:Änderungen sind auf bestimmte Zustände oder Übergänge beschränkt.
- Debugging:Einfacher, Ausführungswege bei Fehlern nachzuverfolgen.
Allerdings haben eingebettete Systeme Einschränkungen. Der Speicher ist begrenzt. Die Verarbeitungsleistung ist endlich. Die Zeitplanung ist entscheidend. Ein Deadlock tritt auf, wenn zwei oder mehr Zustände unendlich aufeinander warten. Dies geschieht oft aufgrund zirkulärer Abhängigkeiten oder Ressourcenkonflikte.
⚠️ Häufige Ursachen von Deadlocks in der Firmware
Bevor Korrekturen angewendet werden, muss man die Ursachen verstehen. Deadlocks in Robotik-Firmware stammen meist daraus, wie Ereignisse in der Warteschlange gehalten werden und wie Ressourcen erworben werden.
1. Zirkuläre Ressourcenabhängigkeit
Zustand A wartet auf eine Ressource, die von Zustand B gehalten wird. Zustand B wartet auf eine Ressource, die von Zustand A gehalten wird. Keiner kann fortfahren. Dies ist typisch für mehrfädige oder mehrprozessige Architekturen.
2. Fehlende Übergangsbedingungen
Wenn eine Übergangsbedingung niemals erfüllt wird, bleibt das System für immer in einem Zustand. Für den Betreiber sieht das wie ein Deadlock aus, obwohl es technisch gesehen ein logischer Stillstand ist.
3. Blockierende Ereigniswarteschlangen
Hochprioritäre Ereignisse hängen hinter niedrigprioritären fest. Wenn die Warteschlange voll ist, werden neue Ereignisse verworfen oder das System blockiert, während es auf Platz wartet.
4. Falsche Fehlerbehandlung
Wenn ein Fehler auftritt, wechselt die Maschine in einen „Fehler“-Zustand. Wenn dieser Zustand keine definierte Ausgangsbedingung hat, hört der Roboter auf, auf alle Eingaben zu reagieren.
🛡️ Best Practices für die Diagrammgestaltung
Die Gestaltung des Diagramms ist die erste Verteidigungslinie. Das visuelle Modell muss in Code übersetzt werden, ohne logische Fehler einzuführen.
1. Klare Eingangs- und Ausgangsaktionen definieren
Jeder Zustand sollte definierte Verhaltensweisen beim Eintritt und Austritt haben. Dadurch wird sichergestellt, dass Ressourcen konsistent verwaltet werden.
- Eingangsaktionen: Variablen initialisieren, Timer starten oder Sensoren aktivieren.
- Austrittsaktionen:Aktuatoren stoppen, Verriegelungen freigeben oder Daten protokollieren.
- Wirkung:Aktionen, die unmittelbar bei einem Übergang ausgeführt werden.
Beispiel:
- Beim Betreten von BewegungZustand: Motorantrieb aktivieren.
- Beim Verlassen von BewegungZustand: Motorantrieb deaktivieren.
2. Verwenden Sie Zustandsverlaufszustände für komplexe Unterzustandsmaschinen
Komplexe Roboter verfügen über verschachtelte Verhaltensweisen. Orthogonale Bereiche ermöglichen die gleichzeitige Ausführung unabhängiger Prozesse. Zustandsverlaufszustände merken sich den zuletzt aktiven Unterzustand.
- Tiefer Verlauf:Geht zurück zum tiefsten aktiven Zustand.
- Flacher Verlauf:Geht zurück zum zuletzt betretenen Zustand auf dieser Ebene.
Dies verhindert, dass das System bei jeder erneuten Eingabe in eine Unterzustandsmaschine auf den Standardzustand zurückgesetzt wird, wodurch Verzögerungen und potenzielle Rennbedingungen reduziert werden.
3. Wächterbedingungen müssen deterministisch sein
Wächter entscheiden, ob ein Übergang stattfindet. Sie müssen schnell und konsistent bewertet werden. Vermeiden Sie komplexe Berechnungen innerhalb von Wächterbedingungen.
- Schlecht: Überprüfung einer langen Liste von Sensordaten mit verschachtelten Schleifen.
- Gut: Überprüfung einer booleschen Flagge, die von einer Hintergrundaufgabe gesetzt wurde.
4. Zeitüberschreitungsübergänge implementieren
Kein Zustand sollte unbegrenzt auf ein Ereignis warten. Eine Zeitüberschreitung stellt Fortschritt sicher.
- Legen Sie eine maximale Dauer für einen Zustand fest.
- Definieren Sie einen Übergang bei Zeitüberschreitung zu einem Fehler- oder Ruhezustand.
- Dies verhindert, dass das System an Netzwerkverzögerungen oder Sensordelay hängen bleibt.
5. Minimieren Sie gleichzeitige Bereiche
Gleichzeitige Bereiche (orthogonale Zustände) sind mächtig, aber riskant. Je mehr Bereiche, desto größer das Potenzial für Synchronisationsfehler.
- Halten Sie Bereiche so weit wie möglich unabhängig.
- Verwenden Sie die Ereignisbroadcasting sorgfältig.
- Vermeiden Sie geteilten veränderbaren Zustand zwischen gleichzeitigen Bereichen.
🔄 Behandlung von Übergängen und Ereignissen
Die Bewegung zwischen Zuständen ist der Bereich, in dem die meisten Logikfehler auftreten. Die Reihenfolge der Ereignisverarbeitung ist von großer Bedeutung.
Ereignispriorisierung
Nicht alle Ereignisse sind gleich. Ein Hardware-Fehler-Ereignis muss ein Statusaktualisierungs-Ereignis überschreiben. Definieren Sie Prioritätsstufen im Diagramm.
Übergangsauslöser
Stellen Sie sicher, dass jeder Zustand auf jedes relevante Ereignis eine definierte Reaktion hat. Wenn ein Ereignis ignoriert wird, wird es als keine Aktion behandelt. Wenn ein Ereignis unerwartet ist, könnte es ein undefiniertes Verhalten auslösen.
Selbstübergänge
Die Verwendung eines Selbstübergangs (Verbleiben im selben Zustand) kann nützlich sein, um Wiederholungen oder Schleifen zu behandeln. Vermeiden Sie jedoch endlose Schleifen innerhalb eines Selbstübergangs ohne eine Abbruchbedingung.
📊 Vergleich von Übergangsstrategien
| Strategie | Vorteile | Nachteile | Deadlock-Risiko |
|---|---|---|---|
| Sofortige Ausführung | Schnellere Reaktionszeit | Schwerer zu unterbrechen | Niedrig |
| Verzögerte Ausführung | Erlaubt Unterbrechung | Höhere Latenz | Mittel |
| Ereigniswarteschlange | Verarbeitet Burst-Ereignisse | Speicherüberhead | Hoch (falls die Warteschlange blockiert) |
| Interruptgesteuert | Echtzeit-Reaktionsfähigkeit | Komplexe Synchronisation | Mittel |
🧩 Ressourcen- und Sperrverwaltung
Die Firmware interagiert oft mit Hardwareperipherien. Diese Ressourcen benötigen exklusiven Zugriff, um Beschädigungen zu vermeiden.
Ressourcenvergabe
Strenge Regeln für das Erhalten von Sperren anwenden.
- Sperren in einer konsistenten Reihenfolge in allen Zuständen erwerben.
- Sperren unmittelbar nach der Verwendung freigeben.
- Eine Sperre niemals halten, während auf eine andere Ressource gewartet wird.
Deadlock-Vermeidungsmatrix
Verwenden Sie eine Matrix, um Ressourcenabhängigkeiten zu verfolgen.
- Alle Zustände auflisten.
- Alle Ressourcen auflisten.
- Markieren Sie, welche Zustände welche Ressourcen halten.
- Zyklen im Abhängigkeitsgraphen identifizieren.
Wenn ein Zyklus existiert, überarbeiten Sie den Zustandsfluss, um ihn zu brechen.
🧪 Testen und Validierung
Das Erstellen des Diagramms ist nur die halbe Arbeit. Die Überprüfung stellt sicher, dass die Implementierung dem Modell entspricht.
Modell-im-Loop-Test
Führen Sie die Zustandsmaschinenlogik in einer Simulationsumgebung aus, bevor sie auf die Hardware bereitgestellt wird. Dadurch ist Stress-Testing möglich, ohne physische Komponenten zu gefährden.
Hardware-im-Loop-Test
Verbinden Sie die Firmware mit einer simulierten physischen Umgebung. Überprüfen Sie zeitliche Beschränkungen und Sensor-Rückkopplungsschleifen.
Fuzz-Test
Rufen Sie zufällige Ereignisse im System auf. Beobachten Sie, ob die Zustandsmaschine unerwartete Eingaben ordnungsgemäß behandelt oder abstürzt.
Protokollierung und Nachverfolgung
Implementieren Sie detaillierte Protokollierung für Zustandsübergänge.
- Protokollieren Sie Ein- und Ausgangszeiten.
- Protokollieren Sie Ereignisauslöser und Übergangsergebnisse.
- Protokollieren der Ressourcenbeschaffung und -freigabe.
Diese Daten sind entscheidend für die Diagnose sporadischer Deadlocks, die nur unter bestimmten Bedingungen auftreten.
🔍 Analyse spezifischer Deadlock-Szenarien
Betrachten wir konkrete Beispiele dafür, wo in der Robotik-Firmware Dinge schief laufen.
Szenario 1: Die Sensor-Wartezeit
Zustand: Warten auf Lidar-Daten.
Bedingung: Übergang nur bei „DataReceived“.
Problem: Wenn der Sensor keine Daten sendet, verlässt der Zustand niemals die Warteschleife. Der Roboter bleibt hängen.
Lösung: Fügen Sie einen Timeout-Übergang hinzu. Wenn „DataReceived“ innerhalb von 5 Sekunden nicht eingeht, wechseln Sie in den Zustand „SensorError“.
Szenario 2: Die Motor-Sperre
Zustand: Akku aufladen.
Bedingung: Übergang in „Idle“, wenn BatteryFull.
Problem: Das Ereignis „BatteryFull“ wird durch eine Ladeschaltung erzeugt. Der Hauptprozessor prüft niemals den Status-Register.
Lösung: Stellen Sie sicher, dass der Interrupt-Handler das Ereignis in die Zustandsmaschinen-Warteschlange einfügt. Verlassen Sie sich nicht auf das Abfragen in einer beschäftigten Schleife.
Szenario 3: Der verschachtelte Aufruf
Zustand:Navigation.
Bedingung: Ruft die Unterfunktion „PathPlanning“ auf.
Problem: „PathPlanning“ blockiert 10 Sekunden lang. Die Zustandsmaschine kann während dieser Zeit keine anderen Ereignisse verarbeiten.
Lösung:Übertragen Sie lange Aufgaben auf einen Hintergrundthread. Senden Sie ein „PlanningComplete“-Ereignis an die Hauptzustandsmaschine.
🔧 Programmierimplementierungs-Muster
Das Diagramm muss sauber in den Code übertragen werden können. Es existieren mehrere Muster, um dies zu erreichen.
Switch-Case-Muster
Verwenden Sie eine Hauptschleife, die auf der aktuellen Zustandsvariablen switcht. Dies ist einfach, kann sich aber bei vielen Zuständen unübersichtlich gestalten.
- Vorteile: Einfach zu lesen für einfache Maschinen.
- Nachteile: Schwierig zu refaktorisieren, anfällig für Tippfehler in Fallbezeichnungen.
Zustandsobjekt-Muster
Jeder Zustand ist eine Klasse, die eine gemeinsame Schnittstelle implementiert. Die Hauptschleife ruft die handle-Methode des aktuellen Zustands auf.
- Vorteile: Verkapselt Logik, leichter erweiterbar.
- Nachteile: Höherer Overhead, höherer Speicherverbrauch.
Tabellenbasierte Herangehensweise
Speichern Sie Übergänge in einer Daten-Tabelle. Die Engine ermittelt den nächsten Zustand basierend auf aktuellem Zustand und Ereignis.
- Vorteile: Sehr konfigurierbar, trennt Daten von Logik.
- Nachteile: Debugging kann schwieriger sein, erfordert eine robuste Engine.
🛠️ Optimierung für eingebettete Einschränkungen
Robotik-Firmware läuft oft auf Mikrocontrollern mit begrenztem RAM und CPU-Leistung.
Speicherverwaltung
- Vermeiden Sie dynamische Zuweisung für Zustandsobjekte während der Laufzeit.
- Reservieren Sie Ereignis-Puffer beim Starten vor.
- Verwenden Sie Puffer mit fester Größe für Zeichenketten und Protokolle.
CPU-Auslastung
- Halten Sie Zustandsübergänge atomar.
- Minimieren Sie die Zeit, die in einem Übergabehandler verbracht wird.
- Verwenden Sie Unterbrechungen nur für Hardware-Ereignisse, nicht für Software-Logik.
📈 Wartung und Evolution
Roboter entwickeln sich weiter. Anforderungen ändern sich. Die Zustandsmaschine muss sich anpassen.
Versionskontrolle
Behalten Sie Zustandsdiagramme zusammen mit dem Quellcode in der Versionskontrolle. Dadurch wird sichergestellt, dass das Modell mit der Implementierung übereinstimmt.
Dokumentation
Beschriften Sie das Diagramm mit Kommentaren, die komplexe Logik erklären. Verlassen Sie sich nicht allein auf das Diagramm.
Refactoring
Beim Hinzufügen neuer Funktionen sollten bestehende Zustände überprüft werden. Stellen Sie sicher, dass die neue Logik keine neuen Deadlock-Pfade einführt.
🚀 Zusammenfassung der wichtigsten Erkenntnisse
Der Aufbau zuverlässiger Robotik-Firmware erfordert diszipliniertes Design. Zustandsmaschinen sind ein mächtiges Werkzeug, erfordern aber eine sorgfältige Verwaltung von Ereignissen und Ressourcen.
- Zeitüberschreitungen definieren:Lassen Sie niemals einen Zustand für immer warten.
- Ressourcen verwalten:Vermeiden Sie zirkuläre Abhängigkeiten.
- Testen Sie gründlich:Verwenden Sie Simulation und Fuzzing.
- Ereignisse überwachen:Stellen Sie sicher, dass alle Eingaben verarbeitet werden.
- Halten Sie es einfach:Verringern Sie die Komplexität, wo immer möglich.
Durch Einhaltung dieser Praktiken können Entwickler Systeme schaffen, die widerstandsfähig und vorhersehbar sind. Der Fokus bleibt auf Funktionalität und Sicherheit. Das Vermeiden von Deadlocks stellt sicher, dass der Roboter seine Mission ohne Unterbrechung abschließt.
🔮 Zukünftige Überlegungen
Da Robotersysteme zunehmend autonome Funktionen aufweisen, müssen Zustandsmaschinen mit höheren Entscheidungsebenen integriert werden. Maschinelles Lernen kann Aktionen vorschlagen, aber die Zustandsmaschine sollte weiterhin die Sicherheitsfunktion übernehmen.
- Stellen Sie sicher, dass die Schnittstellen zwischen KI und Zustandslogik klar definiert sind.
- Erlauben Sie eine sanfte Degradation, falls die KI-Ebene ausfällt.
- Setzen Sie weiterhin deterministisches Verhalten gegenüber probabilistischen Ergebnissen in kritischen Pfaden bevor.
Die Grundlage jedes robusten Systems ist ein klares Verständnis seiner Betriebszustände. Investieren Sie Zeit in die Entwurfsphase. Ein gut strukturiertes Diagramm bringt langfristige Vorteile im Einsatz.
📝 Endgültige Hinweise zur Implementierung
Denken Sie daran, dass das Diagramm ein Vertrag ist. Es definiert, wie das System unter allen Bedingungen reagiert. Behandeln Sie es entsprechend. Überprüfen Sie es mit Kollegen. Prüfen Sie die Annahmen. Testen Sie die Randfälle. Diese Sorgfalt unterscheidet funktionale Prototypen von produktionsreifen Firmware.
Wenn ein Deadlock auftritt, nehmen Sie nicht an, dass es sich um einen Hardwarefehler handelt. Oft ist es ein logischer Fehler. Überprüfen Sie die Zustandsübergänge erneut. Prüfen Sie die Bedingungen. Überprüfen Sie den Ereignisfluss. Die Lösung liegt in der Gestaltung.
Die Einführung dieser besten Praktiken führt zu Systemen, die einfacher zu debuggen sind, sicherer zu betreiben sind und effizienter zu warten sind. Der Weg zur Zuverlässigkeit wird durch klare Zustände und definierte Übergänge gebildet.
