如何為敏捷開發估算使用者故事
估算使用者故事很困難!我們該如何取得最準確的故事規模估算?有些人認為最佳的規模應以故事點來估算,而另一些人則偏好以小時或天數來估算。
確實,估算很困難,但有一些概念能幫助我們在使用者故事估算過程中:
- 從兩個方面以相對方式估算使用者故事
- 工作努力程度
- 風險(例如:複雜性和不確定性)
- 使用故事點來估算使用者故事
- 將那些在工作努力程度和複雜性(風險)方面你有較高信心估算的使用者故事放置於親和力表格中
- 透過與親和力表格中已估算過的故事進行比較,逐步估算其他較不熟悉的使用者故事在工作努力程度和複雜性方面的數值。
用於估算的使用者故事親和力
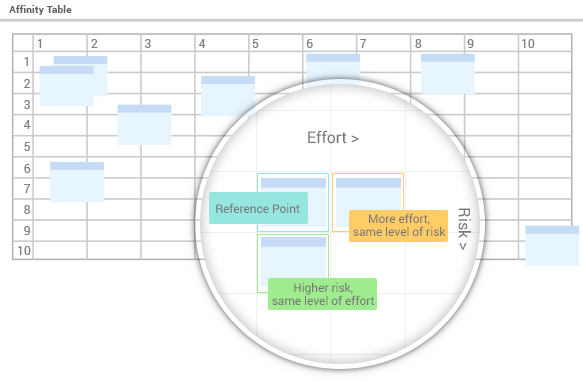
使用者故事的估算永遠無法達到百分之百準確,事實上也沒有任何方法能達成此目標。為了提升估算的準確性,我們首先決定迭代週期長度(例如兩週或10個工作日),並對我們最熟悉的一些使用者故事進行估算(例如5天,且確定性為中等)。在此情況下,你會將該故事置於垂直方向的中間位置(確定性或風險等級)以及水平方向(工作努力程度等於5天,或為迭代週期長度(10天)的一半)。接著你可以將其作為估算其他使用者故事的參考點。問問自己,這個使用者故事是否需要比參考故事更多的努力,或更少,以及是否具有更高的不確定性或更低。當你將更多使用者故事放置於親和力表格上時,可以比較多個故事,以判斷其相對位置是否合理,並加以調整,使其更公平,如此即可。這個過程更像是一門藝術而非工程。應在團隊會議中進行討論,而非對立。隨著團隊日益成熟,估算的準確性通常會提升。
親和力表格如何計算?(觀看影片)
要理解親和力表格中故事點與天數如何自動估算,我們需要了解水平格子代表工作努力程度,由左至右遞增,而故事開發的複雜性(例如新技術、新領域等)則由上至下遞增。
由於使用者故事的開發天數上限應不超過迭代週期(否則,若使用者故事過大,則需拆分,或迭代週期設定過短,需延長),因此右下角格子的天數也應等於迭代週期的長度。基於此假設,故事估算可自動計算。

注意:在上例的第一個範例中
故事點 = 努力程度 × 風險(例如:3 × 4 = 12)
故事點單位 = 總點數 / 迭代週期長度(例如:100 / 20) = 0.2
故事天數(小時) = 故事點 / 故事點單位(例如:12 × 0.2) = 2.4
透過專案突刺消除風險
根據敏捷詞典,Spike 的定義是:
「一個旨在回答問題或收集資訊的任務,而不是產生可交付的產品。有時會產生一個使用者故事,直到開發團隊實際執行一些工作以解決技術問題或設計問題之前,無法進行良好估算。解決方案是建立一個「Spike」,這是一種以提供答案或解決方案為目的的工作。」
在估算使用者故事時,我們不僅考慮開發工作量,還需考慮所涉及的風險和不確定性。通常在正式開始一個衝刺之前,會先建立一個 Spike,以管理為使其他某些使用者故事能公平估算而必須執行的工作。
