











引言
軟體架構的面貌正經歷著劇烈的轉變。數十年來,任何穩健應用程式的基礎——資料庫——都是透過嚴謹的手動勞動所構思而成。這個過程被稱為資料庫建模的演進,如今正從手動藍圖的時代轉向一個新的時代人工智慧驅動的架構.
傳統上,設計資料結構需要深厚的專業知識、孤立的工具以及大量的時間投入。這是一個高摩擦的過程,容易出現人為錯誤、重複以及架構負債。然而,像Visual Paradigm 的資料庫模型人工智慧之類的創新已打破這種現狀。透過引入智慧且導向性的七步工作流程,此技術利用生成式人工智慧,將普通的英文描述轉換為完全規範化且可投入生產的資料庫結構。
本全面指南探討了這一演進過程,強調了傳統方法與現代人工智慧能力之間的顯著差異。我們將透過一個經典的線上書店情境,展示人工智慧如何消除傳統的痛點,並加速專業資料庫設計的進程。
傳統的困境:手動限制與高摩擦
在人工智慧出現之前,資料庫建模被視為一種勞力密集的專業技藝,僅限於專家從事。這個過程充滿挑戰,經常拖慢開發週期並引入漏洞。
傳統工作流程
- 空白畫布:設計師會使用 ER/Studio、Lucidchart,甚至實體的筆和紙,從空的作業空間開始。毫無起點優勢;每個實體都必須從零開始構思。
- 手動識別:架構師必須手動識別實體, 屬性, 關係, 主要鍵(PKs),以及外鍵 (FKs)這需要在畫下任何一筆之前,就具備完美的商業邏輯心智模型。
- 規範化的困擾:從草圖轉換到已部署的資料結構,涉及規範化(1NF → 2NF → 3NF)。此過程尋找重複資料、部分依賴與傳遞依賴。傳統上,這需要費心費力的手動分析,極易忽略問題且容易出錯。
- 被動工具:傳統工具僅如同數位繪圖板。它們不提供智能建議,無法在概念模型與邏輯模型之間自動轉換,也沒有超出基本語法檢查的驗證功能。
- 測試孤島:驗證需要建立本地資料庫環境(例如:PostgreSQL、MySQL),手動撰寫
INSERT指令碼,並希望查詢能揭露完整性問題。
這種手動方法的結果,通常會產生顯著的架構負債、冗長的迭代週期,以及陡峭的學習曲線,使產品經理或學生等非專家無法參與設計過程。
AI驅動的范式轉變
DB Modeler AI,可透過Visual Paradigm 的線上平台,代表我們處理資料方式的根本性改變。它不僅僅是工具,更像是一位「智慧副駕駛」。透過運用自然語言處理 (NLP)與廣泛的領域知識,它能理解商業需求,並生成符合標準的模型。
對比:傳統方法與AI驅動建模
下表概述了傳統手動方法與現代AI驅動工作流程之間的主要運作差異。
| 功能 | 傳統手動方法 | AI驅動方法(DB Modeler AI) |
|---|---|---|
| 輸入機制 | 手動拖曳與放置;明確定義每一欄。 | 自然語言(普通英文描述)。 |
| 速度 | 複雜資料結構需數天或數週。 | 從概念到標準化模式僅需數分鐘。 |
| 標準化 | 手動分析;容易出現人為錯誤和疏漏。 | 自動化、逐步引導(1NF、2NF、3NF)並附有說明。 |
| 驗證 | 需要外部資料庫設定與手動撰寫指令碼。 | 即時的瀏覽器內SQL沙盒,搭配AI生成的測試資料。 |
| 可及性 | 需要深厚的SQL/架構知識。 | 開發人員、專案經理、學生與架構師皆可使用。 |
| 輸出品質 | 完全取決於使用者的專業程度。 | 標準化、符合最佳實務、可直接投入生產環境的DDL。 |
七步引導式工作流程
Visual Paradigm其資料庫模型AI採用透明的七步流程,引導使用者從模糊概念逐步轉化為具體且經過測試的資料庫模式。
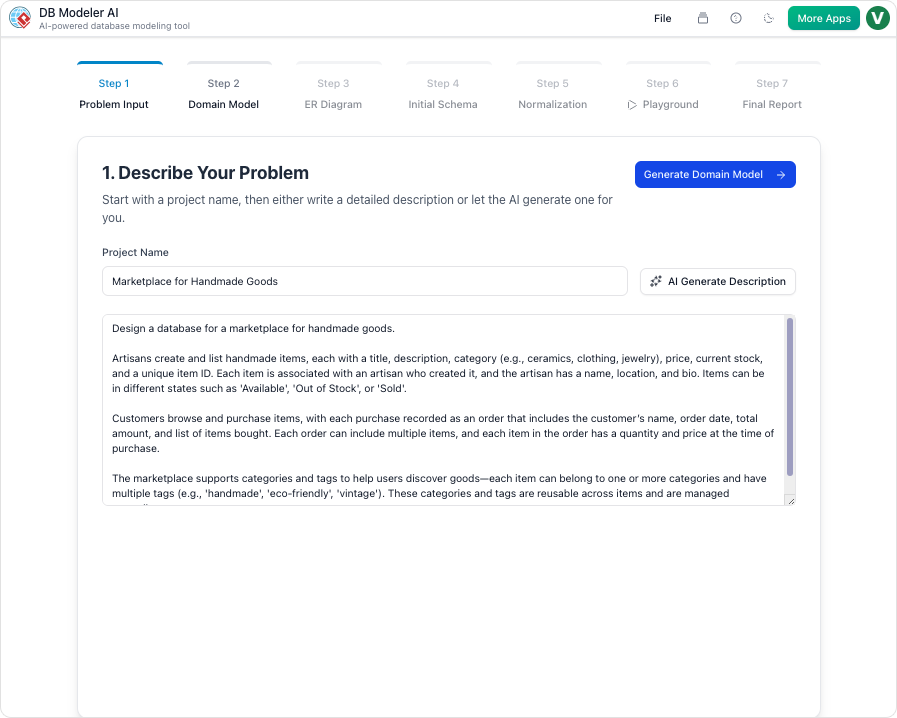
1. 問題輸入
流程從一個簡單的提示開始。使用者以白話英文描述其應用程式。例如:「建立一個線上書店的資料庫,用以管理書籍、作者、客戶、訂單,並支援追蹤運送狀態。」AI會分析此段文字以提取核心需求。
2. 領域類別圖
在深入表格與鍵值之前,AI會使用PlantUML語法生成高階的概念視圖。這有助於以抽象方式呈現物件及其關係,確保在技術實作前範圍正確。
3. 資料實體關係圖產生
系統會自動從概念模型轉換為詳細的邏輯實體-關係圖(ERD)。自動定義表格、欄位、基數、主鍵與外鍵。
4. 初始模式產生
ERD會轉換為SQL資料定義語言(DDL)。該工具通常預設採用廣泛使用的標準,如PostgreSQL,確保與現代技術架構相容。
5. 智能標準化
這無疑是最重要的一步。AI會逐步優化模式,以確保資料完整性:
- 1NF(第一範式): 確保原子性。它消除了多值欄位(例如,確保單元格不包含以逗號分隔的作者列表)。
- 2NF(第二範式): 消除部分依賴。它確保非鍵屬性依賴於整個主鍵,通常會拆分表格(例如,將作者詳情與書籍表格分離)。
- 3NF(第三範式): 消除傳遞依賴。它確保欄位僅依賴於主鍵,而不依賴於其他非鍵欄位。
關鍵的是,AI提供教育性的理由用於每一項決策,解釋為什麼表格被拆分的原因,使其成為一個強大的學習工具。
6. 互動式沙盒
該工具無需本地伺服器,而是提供基於瀏覽器的SQL環境。它會自動以真實且由AI生成的樣本資料填入資料結構。這使得能夠立即測試查詢和CRUD操作。
7. 最終報告與匯出
驗證後,使用者可產生Markdown格式的設計報告,匯出SQL指令碼,並以PDF或JSON格式下載圖表。這可作為開發團隊的「唯一可信來源」。
實務範例:設計線上書店
為了展示此工作流程的強大之處,讓我們將其應用於線上書店在原始資料中提到的情境。
步驟1:提示
我們輸入以下需求:「我需要一個線上書店的系統,用於管理書籍(包含書名、作者、價格、分類、ISBN)、客戶(姓名、電子郵件、地址)、訂單(日期、狀態、總額)以及訂單項目。客戶可依作者或分類瀏覽,下訂單並追蹤運送狀態。」
步驟2與3:結構可視化
AI立即建立一個領域類圖接著建立一個實體關係圖。它識別出一個客戶擁有1:N 與 … 的關係訂單,以及書籍具有N:M(多對多)關係與訂單,因此需要一個中介訂單項目表格。
步驟 4 與 5:優化與規範化
最初,資料結構可能會將作者姓名直接儲存在書籍表格中。AI 識別出這違反了最佳資料庫設計。
- 行動:AI 將
作者提取至其自身的表格。 - 結果:原本的
書籍表格現在包含一個作者編號外鍵。 - 優勢:這消除了重複;若作者更改姓名,只需在一個地方更新即可。
步驟 6:在沙盒中測試
在產生資料結構後,AI 使用真實資料填入資料庫(例如,F. 斯科特·菲茨傑拉德所著的《大亨小傳》)。我們可以立即執行測試查詢以驗證結構:
SELECT b.title, a.name
FROM books b
JOIN authors a ON b.author_id = a.id
WHERE b.category = '小說';如果查詢返回預期結果,設計將立即得到驗證。
結論:減少架構債務
從手動藍圖到由人工智慧驅動的架構透過類似於Visual Paradigm DB Modeler AI使高品質的資料庫設計普及化。它彌合了概念性商業需求與技術實現之間的差距。
過去需要數週專家勞動且伴隨高昂錯誤風險的工作,如今可在數分鐘內完成。透過內建的教育、驗證與協作功能,此技術賦予學生、產品經理與開發人員更快、更可靠的資料架構建置能力。隨著我們向前發展,將人工智慧整合至資料庫建模的基礎階段,很可能會成為減少架構債務與加速創新之標準。
